Bitte beachte, dass dies keine Einführungsstunde ist. Bitte lesen Sie Was ist Apache Kafka und wie funktioniert es, bevor Sie mit dieser Lektion fortfahren, um einen tieferen Einblick zu erhalten.
Themen in Kafka
Ein Thema in Kafka ist etwas, wo eine Nachricht gesendet wird. Die Verbraucheranwendungen, die an diesem Thema interessiert sind, ziehen die Nachricht in dieses Thema und können alles mit diesen Daten machen. Bis zu einem bestimmten Zeitpunkt können beliebig viele Verbraucheranwendungen diese Nachricht beliebig oft abrufen pull.
Betrachten Sie ein Thema wie die Ubuntu-Blog-Seite von LinuxHint. Die Lektionen dauern bis in die Ewigkeit und eine beliebige Anzahl von begeisterten Lesern kann diese Lektionen beliebig oft lesen oder nach Belieben zur nächsten Lektion wechseln lesson. Diese Leser können sich auch für andere Themen von LinuxHint interessieren.
Themenpartitionierung
Kafka wurde entwickelt, um umfangreiche Anwendungen zu verwalten und eine große Anzahl von Nachrichten in eine Warteschlange zu stellen, die in einem Thema aufbewahrt werden. Um eine hohe Fehlertoleranz zu gewährleisten, wird jedes Thema in mehrere Themenpartitionen unterteilt und jede Themenpartition wird auf einem separaten Knoten verwaltet. Wenn einer der Knoten ausfällt, kann ein anderer Knoten als Themenführer fungieren und Themen an die interessierten Verbraucher senden server. So werden dieselben Daten in mehrere Themenpartitionen geschrieben: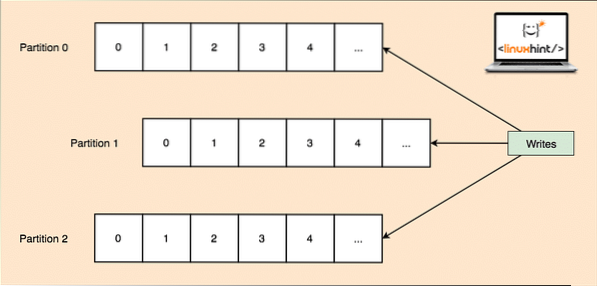
Themenpartitionen
Das obige Bild zeigt nun, wie dieselben Daten über mehrere Partitionen repliziert werden. Lassen Sie uns visualisieren, wie verschiedene Partitionen auf verschiedenen Knoten/Partitionen als Leader fungieren können:
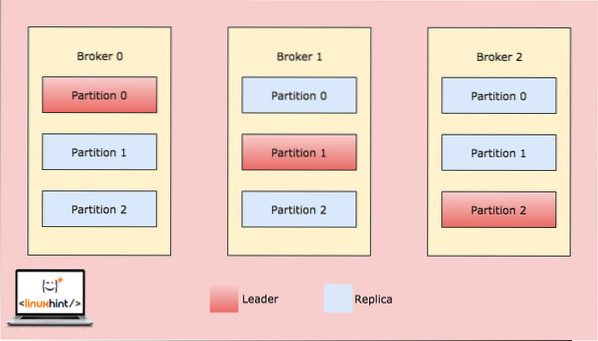
Kafka Broker-Partitionierung
Wenn ein Client etwas in ein Thema an einer Position schreibt, für die Partition in Broker 0 führend ist, werden diese Daten dann über die Broker/Knoten repliziert, damit die Nachricht sicher bleibt: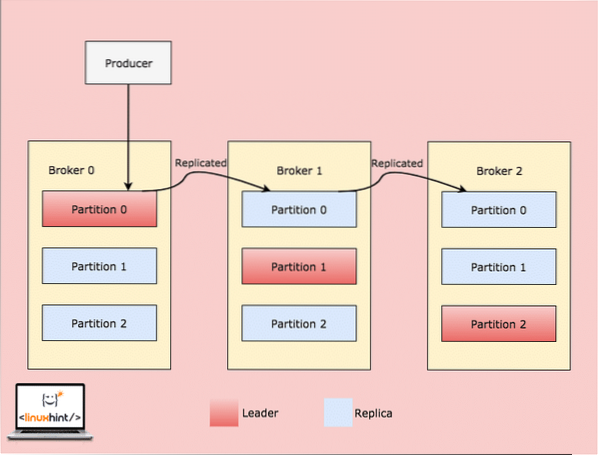
Replikation über Broker-Partitionen
Mehr Partitionen, höherer Durchsatz
Kafka macht Gebrauch von Parallelität um einen sehr hohen Durchsatz für Hersteller- und Verbraucheranwendungen bereitzustellen. Tatsächlich behält es auf die gleiche Weise auch seinen Status als hochfehlertolerantes System bei. Lassen Sie uns verstehen, wie mit Parallelismus ein hoher Durchsatz erreicht wird.
Wenn eine Producer-Anwendung eine Nachricht in eine Partition in Broker 0 schreibt, öffnet Kafka mehrere Threads parallel, damit die Nachricht auf allen ausgewählten Brokern gleichzeitig repliziert werden kann. Auf der Consumer-Seite konsumiert eine Consumer-Anwendung Nachrichten von einer einzelnen Partition über einen Thread. Je höher die Anzahl der Partitionen, desto mehr Consumer-Threads können geöffnet werden, sodass alle auch parallel arbeiten können. Das bedeutet, je mehr Partitionen in einem Cluster vorhanden sind, desto mehr Parallelität kann ausgenutzt werden, wodurch ein System mit sehr hohem Durchsatz entsteht.
Mehr Partitionen brauchen mehr Dateihandler
Nur damit Sie oben studiert haben, wie wir die Leistung eines Kafka-Systems steigern können, indem Sie einfach die Anzahl der Partitionen erhöhen. Aber wir müssen aufpassen, auf welche Grenze wir uns bewegen.
Jede Themenpartition in Kafka wird einem Verzeichnis im Dateisystem des Server-Brokers zugeordnet, auf dem sie ausgeführt wird. In diesem Protokollverzeichnis befinden sich zwei Dateien: eine für den Index und eine weitere für die eigentlichen Daten pro Logsegment. Derzeit öffnet in Kafka jeder Broker ein Dateihandle sowohl für den Index als auch für die Datendatei jedes Logsegments. Das bedeutet, dass bei 10.000 Partitionen auf einem einzelnen Broker 20.000 Dateihandler parallel laufen. Allerdings geht es hier nur um die Konfiguration des Brokers. Wenn das System, auf dem der Broker bereitgestellt wird, eine hohe Konfiguration hat, wird dies kaum ein Problem sein.
Risiko bei hoher Anzahl von Partitionen
Wie wir in den obigen Bildern gesehen haben, verwendet Kafka die Intra-Cluster-Replikationstechnik, um eine Nachricht von einem Leader an die Replikatpartitionen zu replizieren, die in anderen Brokern liegen. Sowohl die Producer- als auch die Consumer-Anwendung lesen und schreiben auf eine Partition, die derzeit der führende Anbieter dieser Partition ist. Wenn ein Broker ausfällt, wird der Leiter dieses Brokers nicht verfügbar. Die Metadaten darüber, wer der Anführer ist, werden in Zookeeper gespeichert. Basierend auf diesen Metadaten weist Kafka die Führung der Partition automatisch einer anderen Partition zu.
Wenn ein Broker mit einem sauberen Befehl heruntergefahren wird, verschiebt der Controller-Knoten des Kafka-Clusters die Leiter des herunterfahrenden Brokers seriell i.e. eins nach dem anderen. Wenn wir bedenken, dass das Verschieben eines einzelnen Anführers 5 Millisekunden dauert, wird die Nichtverfügbarkeit der Anführer die Verbraucher nicht stören, da die Nichtverfügbarkeit nur für einen sehr kurzen Zeitraum erfolgt. Aber wenn wir bedenken, wann der Broker auf unsaubere Weise getötet wird und dieser Broker 5000 Partitionen enthält und von diesen 2000 die Partitionsführer waren, dauert die Zuweisung neuer Leader für all diese Partitionen 10 Sekunden, was sehr hoch ist, wenn es um hoch geht gefragte Anwendungen.
Fazit
Wenn wir als High-Level-Denker betrachten, führen mehr Partitionen in einem Kafka-Cluster zu einem höheren Durchsatz des Systems. Angesichts dieser Effizienz muss man auch die Konfiguration des Kafka-Clusters berücksichtigen, den wir pflegen müssen, den Speicher, den wir diesem Cluster zuweisen müssen und wie wir die Verfügbarkeit und Latenz verwalten können, wenn etwas schief geht.
Lesen Sie hier mehr Ubuntu-basierte Beiträge und vieles mehr über Apache Kafka.


