Dieser Überblick ist etwas abstrakt, also lassen Sie uns ihn in einem realen Szenario erden. Stellen Sie sich vor, Sie müssen mehrere Webserver überwachen monitor. Jeder betreibt seine eigene Website, und in jedem von ihnen werden jede Sekunde des Tages ständig neue Protokolle generiert. Darüber hinaus gibt es eine Reihe von E-Mail-Servern, die Sie ebenfalls überwachen müssen.
Möglicherweise müssen Sie diese Daten zu Aufzeichnungs- und Abrechnungszwecken speichern, was ein Batch-Job ist, der keine sofortige Aufmerksamkeit erfordert. Möglicherweise möchten Sie Analysen der Daten durchführen, um Entscheidungen in Echtzeit zu treffen, was eine genaue und sofortige Dateneingabe erfordert requires. Plötzlich sehen Sie sich in der Notwendigkeit, die Daten für all die verschiedenen Bedürfnisse sinnvoll zu straffen. Kafka fungiert als die Abstraktionsebene, auf der mehrere Quellen unterschiedliche Datenströme und eine gegebene Veröffentlichung veröffentlichen können Verbraucher kann die Streams abonnieren, die es für relevant hält. Kafka sorgt dafür, dass die Daten geordnet sind. Es sind die Interna von Kafka, die wir verstehen müssen, bevor wir zum Thema Partitionierung und Schlüssel kommen.
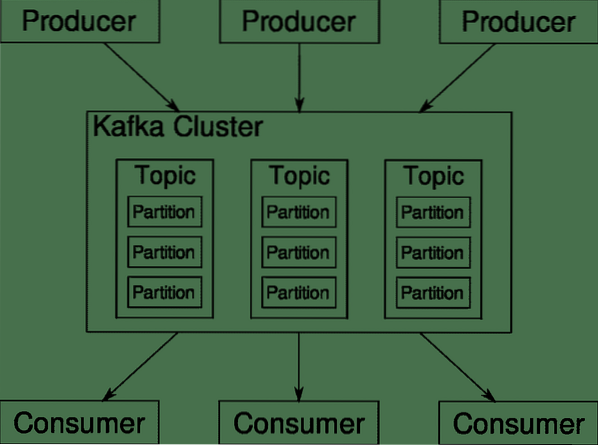
Kafka-Themen, Broker und Partitionen
Kafka Themen sind wie Tabellen einer Datenbank. Jedes Thema besteht aus Daten aus einer bestimmten Quelle eines bestimmten Typs. Der Zustand Ihres Clusters kann beispielsweise ein Thema sein, das aus Informationen zur CPU- und Arbeitsspeicherauslastung besteht. Ebenso kann eingehender Datenverkehr im gesamten Cluster ein weiteres Thema sein.
Kafka ist horizontal skalierbar. Das heißt, eine einzelne Instanz von Kafka besteht aus mehreren Kafka Makler läuft über mehrere Knoten, jeder kann Datenströme parallel zum anderen verarbeiten handle. Selbst wenn einige der Knoten ausfallen, kann Ihre Datenpipeline weiterhin funktionieren. Ein bestimmtes Thema kann dann in mehrere unterteilt werden Partitionen. Diese Aufteilung ist einer der entscheidenden Faktoren für die horizontale Skalierbarkeit von Kafka.
Mehrere Hersteller, Datenquellen für ein bestimmtes Thema können gleichzeitig in dieses Thema schreiben, da jede zu einem bestimmten Zeitpunkt in eine andere Partition schreibt write. Normalerweise werden Daten einer Partition nach dem Zufallsprinzip zugewiesen, es sei denn, wir versehen sie mit einem Schlüssel.
Partitionierung und Bestellung
Nur um es zusammenzufassen: Produzenten schreiben Daten zu einem bestimmten Thema. Dieses Thema ist tatsächlich in mehrere Partitionen aufgeteilt. Und jede Partition lebt unabhängig von den anderen, auch für ein bestimmtes Thema. Dies kann zu viel Verwirrung führen, wenn es um die Bestellung von Daten geht. Vielleicht benötigen Sie Ihre Daten in chronologischer Reihenfolge, aber mehrere Partitionen für Ihren Datenstrom garantieren keine perfekte Ordnung.
Sie können nur eine einzige Partition pro Thema verwenden, aber das verfehlt den ganzen Zweck der verteilten Architektur von Kafka. Also brauchen wir eine andere Lösung.
Schlüssel für Partitionen
Daten von einem Produzenten werden zufällig an Partitionen gesendet, wie bereits erwähnt. Nachrichten sind die eigentlichen Datenblöcke. Was Produzenten neben dem Versenden von Nachrichten tun können, ist, einen dazugehörigen Schlüssel hinzuzufügen.
Alle Nachrichten, die mit dem spezifischen Schlüssel geliefert werden, gehen an dieselbe Partition. So kann beispielsweise die Aktivität eines Benutzers chronologisch verfolgt werden, wenn die Daten dieses Benutzers mit einem Schlüssel versehen sind und so immer in einer Partition landen. Nennen wir diese Partition p0 und den Benutzer u0.
Partition p0 wird immer die u0-bezogenen Nachrichten aufnehmen, da dieser Schlüssel sie zusammenhält. Das heißt aber nicht, dass p0 nur damit verbunden ist. Es kann auch Nachrichten von u1 und u2 aufnehmen, wenn es die Kapazität dazu hat. Ebenso können andere Partitionen Daten von anderen Benutzern verbrauchen.
Der Punkt, dass die Daten eines bestimmten Benutzers nicht auf verschiedene Partitionen verteilt sind, um eine chronologische Reihenfolge für diesen Benutzer zu gewährleisten. Das Gesamtthema Benutzerdaten, kann weiterhin die verteilte Architektur von Apache Kafka nutzen leverage.
Fazit
Während verteilte Systeme wie Kafka einige ältere Probleme wie mangelnde Skalierbarkeit oder einzelne Fehlerquellen lösen. Sie kommen mit einer Reihe von Problemen, die für ihr eigenes Design einzigartig sind. Diese Probleme zu antizipieren ist eine wesentliche Aufgabe eines jeden Systemarchitekten. Darüber hinaus muss man manchmal wirklich eine Kosten-Nutzen-Analyse durchführen, um festzustellen, ob die neuen Probleme ein würdiger Kompromiss sind, um die älteren loszuwerden. Bestellung und Synchronisation sind nur die Spitze des Eisbergs.
Hoffentlich können Ihnen Artikel wie diese und die offizielle Dokumentation dabei helfen.


