Teil 1: Einrichten eines einzelnen Knotens
Die elektronische Speicherung Ihrer Dokumente oder Daten auf einem Datenträger ist heute schnell und einfach und zudem vergleichsweise günstig. In Verwendung ist eine Dateinamensreferenz, die beschreiben soll, worum es in dem Dokument geht. Alternativ werden die Daten in einem Database Management System (DBMS) wie PostgreSQL, MariaDB oder MongoDB gehalten, um nur einige Optionen zu nennen. Mehrere Speichermedien sind entweder lokal oder remote mit dem Computer verbunden, wie USB-Stick, interne oder externe Festplatte, Network Attached Storage (NAS), Cloud Storage oder GPU/Flash-basiert wie bei einer Nvidia V100 [10].
Der umgekehrte Prozess, die richtigen Dokumente in einer Dokumentensammlung zu finden, ist dagegen eher komplex. Es erfordert meistens das fehlerfreie Erkennen des Dateiformats, das Indizieren des Dokuments und das Extrahieren der Schlüsselkonzepte (Dokumentklassifizierung). Hier kommt das Apache Solr-Framework ins Spiel. Es bietet eine praktische Schnittstelle, um die genannten Schritte auszuführen - einen Dokumentenindex erstellen, Suchanfragen annehmen, die eigentliche Suche durchführen und ein Suchergebnis zurückgeben. Apache Solr bildet somit den Kern für eine effektive Recherche in einem Datenbank- oder Dokumentensilo.
In diesem Artikel erfahren Sie, wie Apache Solr funktioniert, wie Sie einen einzelnen Knoten einrichten, Dokumente indizieren, eine Suche durchführen und das Ergebnis abrufen.
Darauf bauen die Folgeartikel auf, in denen wir weitere, spezifischere Anwendungsfälle wie die Integration eines PostgreSQL-DBMS als Datenquelle oder den Lastenausgleich über mehrere Knoten diskutieren.
Über das Apache Solr-Projekt
Apache Solr ist ein Suchmaschinen-Framework basierend auf dem leistungsstarken Lucene-Suchindexserver [2]. Es ist in Java geschrieben und wird unter dem Dach der Apache Software Foundation (ASF) gepflegt [6]. Es ist unter der Apache 2-Lizenz frei verfügbar.
Das Thema „Dokumente und Daten wiederfinden“ spielt in der Softwarewelt eine sehr wichtige Rolle und viele Entwickler beschäftigen sich intensiv damit. Die Website Awesomeopensource [4] listet mehr als 150 Open-Source-Projekte für Suchmaschinen auf. Ab Anfang 2021 sind ElasticSearch [8] und Apache Solr/Lucene die beiden Platzhirsche, wenn es um die Suche nach größeren Datensätzen geht. Die Entwicklung Ihrer Suchmaschine erfordert viel Wissen, das macht Frank mit der Python-basierten AdvaS Advanced Search [3]-Bibliothek seit 2002.
Apache Solr einrichten:
Die Installation und der Betrieb von Apache Solr sind nicht kompliziert, es sind einfach eine ganze Reihe von Schritten die von Ihnen ausgeführt werden müssen. Warten Sie etwa 1 Stunde für das Ergebnis der ersten Datenabfrage. Darüber hinaus ist Apache Solr nicht nur ein Hobbyprojekt, sondern wird auch im professionellen Umfeld eingesetzt. Daher ist die gewählte Betriebssystemumgebung auf den langfristigen Einsatz ausgelegt.
Als Basisumgebung für diesen Artikel verwenden wir Debian GNU/Linux 11, die kommende Debian-Veröffentlichung (ab Anfang 2021) und voraussichtlich Mitte 2021 verfügbar sein. Für dieses Tutorial erwarten wir, dass Sie es bereits installiert haben – entweder als natives System, in einer virtuellen Maschine wie VirtualBox oder einem AWS-Container.
Neben den Basiskomponenten müssen folgende Softwarepakete auf dem System installiert werden:
- Locken
- Standard-Java
- Libcommons-cli-java
- Libxerces2-java
- Libtika-java (eine Bibliothek aus dem Apache Tika-Projekt [11])
Diese Pakete sind Standardkomponenten von Debian GNU/Linux. Falls noch nicht installiert, können Sie diese als Benutzer mit administrativen Rechten, zum Beispiel root oder per sudo, in einem Rutsch nachinstallieren, wie folgt dargestellt:
# apt-get install curl default-java libcommons-cli-java libxerces2-java libtika-javaNachdem die Umgebung vorbereitet wurde, ist der 2. Schritt die Installation von Apache Solr. Derzeit ist Apache Solr nicht als reguläres Debian-Paket verfügbar. Daher ist es erforderlich, Apache Solr 8 abzurufen.8 aus dem Downloadbereich der Projektwebsite [9] zuerst. Verwenden Sie den folgenden Befehl wget, um ihn im Verzeichnis /tmp Ihres Systems zu speichern:
$ wget -O /tmp https://downloads.Apache.org/Lucen/solr/8.8.0/solr-8.8.0.tgzDer Schalter -O verkürzt -output-document und lässt wget das abgerufene Tar speichern.gz-Datei im angegebenen Verzeichnis. Das Archiv hat eine Größe von ca. 190M. Als nächstes entpacken Sie das Archiv mit tar . in das Verzeichnis /opt. Als Ergebnis finden Sie zwei Unterverzeichnisse - /opt/solr und /opt/solr-8.8.0, während /opt/solr als symbolischer Link zu letzterem eingerichtet ist. Apache Solr wird mit einem Setup-Skript geliefert, das Sie als nächstes ausführen. Es lautet wie folgt:
# /opt/solr-8.8.0/bin/install_solr_service.SchDies führt zur Erstellung des Linux-Benutzers solr läuft im Solr-Dienst plus seinem Home-Verzeichnis unter /var/solr baut den Solr-Dienst auf, fügt ihn mit seinen entsprechenden Knoten hinzu und startet den Solr-Dienst auf Port 8983. Dies sind die Standardwerte. Wenn Sie mit ihnen nicht zufrieden sind, können Sie sie während der Installation oder sogar später ändern, da das Installationsskript entsprechende Schalter für Setup-Anpassungen akzeptiert. Wir empfehlen Ihnen einen Blick in die Apache Solr-Dokumentation zu diesen Parametern.
Die Solr-Software ist in folgenden Verzeichnissen organisiert:
- Behälter
enthält die Solr-Binärdateien und -Dateien, um Solr als Dienst auszuführen - beitragen
externe Solr-Bibliotheken wie Datenimport-Handler und die Lucene-Bibliotheken - dist
interne Solr-Bibliotheken - Dokumente
Link zur online verfügbaren Solr-Dokumentation - Beispiel
Beispieldatensätze oder mehrere Anwendungsfälle/Szenarien - Lizenzen
Softwarelizenzen für die verschiedenen Solr-Komponenten - Server
Serverkonfigurationsdateien, wie Server/etc für Dienste und Ports
Ausführlichere Informationen zu diesen Verzeichnissen finden Sie in der Apache Solr-Dokumentation [12].
Verwalten von Apache Solr:
Apache Solr läuft als Dienst im Hintergrund. Sie können es auf zwei Arten starten, entweder mit systemctl (erste Zeile) als Benutzer mit Administratorrechten oder direkt aus dem Solr-Verzeichnis (zweite Zeile). Wir listen beide Terminalbefehle unten auf:
# systemctl start solr$ solr/bin/solr start
Das Stoppen von Apache Solr erfolgt auf ähnliche Weise:
# systemctl stop solr$ solr/bin/solr stop
Auf die gleiche Weise wird der Apache Solr-Dienst neu gestartet:
# systemctl restart solr$ solr/bin/solr Neustart
Darüber hinaus kann der Status des Apache Solr-Prozesses wie folgt angezeigt werden:
# systemctl status solr$ solr/bin/solr-Status
Die Ausgabe listet die gestartete Servicedatei auf, sowohl den entsprechenden Zeitstempel als auch die Protokollmeldungen. Die folgende Abbildung zeigt, dass der Apache Solr-Dienst auf Port 8983 mit Prozess 632 gestartet wurde. Der Prozess läuft erfolgreich für 38 Minuten.
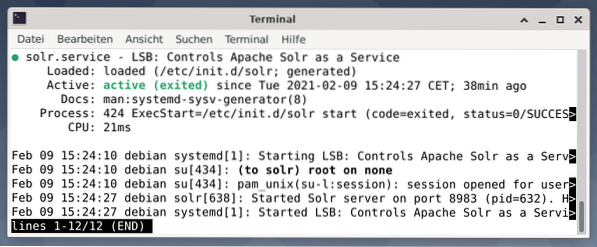
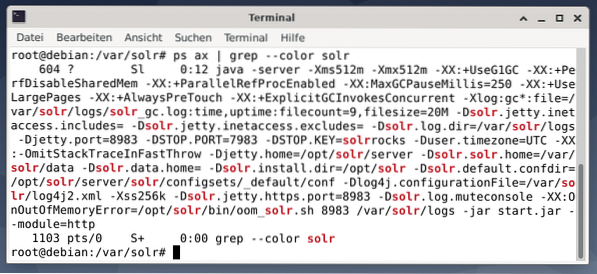
Um zu sehen, ob der Apache Solr-Prozess aktiv ist, können Sie auch den Befehl ps in Kombination mit grep verwenden. Dadurch wird die ps-Ausgabe auf alle derzeit aktiven Apache Solr-Prozesse beschränkt.
# ps axt | grep --color solrDie folgende Abbildung zeigt dies für einen einzelnen Prozess. Sie sehen den Aufruf von Java, der von einer Liste von Parametern begleitet wird, zum Beispiel Speichernutzung (512M) Ports zum Abhören von 8983 für Abfragen, 7983 für Stoppanforderungen und Verbindungstyp (http).
Hinzufügen von Benutzern:
Die Apache Solr-Prozesse laufen mit einem bestimmten Benutzer namens solr. Dieser Benutzer ist hilfreich bei der Verwaltung von Solr-Prozessen, dem Hochladen von Daten und dem Senden von Anfragen. Bei der Einrichtung hat der Benutzer solr kein Passwort und es wird erwartet, dass er sich einloggt, um fortzufahren. Legen Sie ein Passwort für den Benutzer solr wie den Benutzer root fest, es wird wie folgt angezeigt:
# passwd solrSolr-Verwaltung:
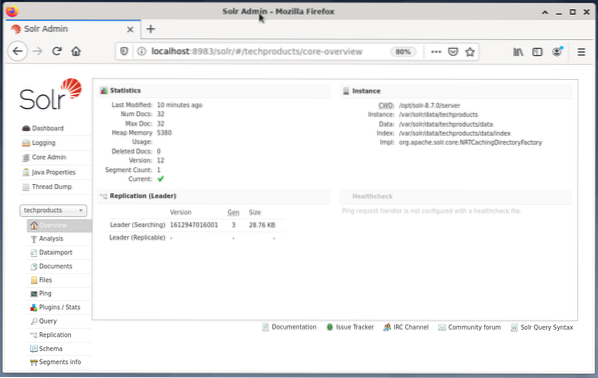
Die Verwaltung von Apache Solr erfolgt über das Solr-Dashboard. Dies ist über einen Webbrowser von http://localhost:8983/solr . zugänglich. Die Abbildung unten zeigt die Hauptansicht.
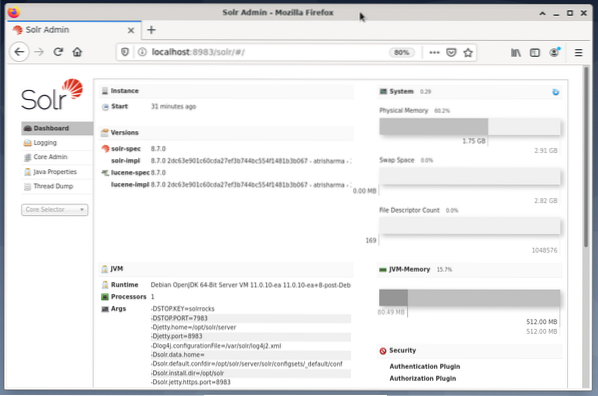
Auf der linken Seite sehen Sie das Hauptmenü, das Sie zu den Unterpunkten für das Logging, die Administration der Solr-Cores, das Java-Setup und die Statusinformationen führt. Wählen Sie den gewünschten Kern über das Auswahlfeld unterhalb des Menüs. Auf der rechten Seite des Menüs werden die entsprechenden Informationen angezeigt. Der Menüeintrag Dashboard zeigt weitere Details zum Apache Solr-Prozess sowie die aktuelle Auslastung und Speichernutzung an.
Bitte beachten Sie, dass sich der Inhalt des Dashboards je nach Anzahl der Solr-Kerne und der indizierten Dokumente ändert changes. Änderungen betreffen sowohl die Menüpunkte als auch die entsprechenden rechts sichtbaren Informationen.
Verstehen, wie Suchmaschinen funktionieren:
Einfach gesagt, Suchmaschinen analysieren Dokumente, kategorisieren sie und ermöglichen Ihnen eine Suche basierend auf ihrer Kategorisierung. Grundsätzlich besteht der Prozess aus drei Phasen, die als Crawling, Indexing und Ranking bezeichnet werden [13].
Krabbeln ist die erste Stufe und beschreibt einen Prozess, bei dem neue und aktualisierte Inhalte gesammelt werden. Die Suchmaschine verwendet Roboter, die auch als Spider oder Crawler bekannt sind, daher der Begriff Crawling, um verfügbare Dokumente zu durchsuchen.
Die zweite Stufe heißt Indizierung. Die zuvor gesammelten Inhalte werden durchsuchbar gemacht, indem die Originaldokumente in ein Format umgewandelt werden, das die Suchmaschine versteht. Schlüsselwörter und Konzepte werden extrahiert und in (massiven) Datenbanken gespeichert.
Die dritte Stufe heißt Rangfolge und beschreibt den Vorgang der Sortierung der Suchergebnisse nach Relevanz bei einer Suchanfrage. Es ist üblich, die Ergebnisse in absteigender Reihenfolge anzuzeigen, damit das Ergebnis mit der höchsten Relevanz für die Suchanfrage des Suchenden an erster Stelle steht.
Apache Solr funktioniert ähnlich wie der zuvor beschriebene dreistufige Prozess. Wie die beliebte Suchmaschine Google verwendet Apache Solr eine Sequenz zum Sammeln, Speichern und Indizieren von Dokumenten aus verschiedenen Quellen und macht sie nahezu in Echtzeit verfügbar/durchsuchbar.
Apache Solr verwendet verschiedene Methoden, um Dokumente zu indizieren, einschließlich der folgenden [14]:
- Verwendung eines Index-Request-Handlers beim direkten Hochladen der Dokumente in Solr. Diese Dokumente sollten im JSON-, XML/XSLT- oder CSV-Format vorliegen.
- Verwenden des Extraktions-Request-Handlers (Solr Cell). Die Dokumente sollten im PDF- oder Office-Format vorliegen, die von Apache Tika . unterstützt werden.
- Verwenden des Datenimport-Handlers, der Daten aus einer Datenbank übermittelt und sie anhand von Spaltennamen katalogisiert. Der Data Import Handler ruft Daten aus E-Mails, RSS-Feeds, XML-Daten, Datenbanken und Nur-Text-Dateien als Quellen ab.
In Apache Solr wird ein Abfragehandler verwendet, wenn eine Suchanfrage gesendet wird. Der Abfragehandler analysiert die gegebene Abfrage basierend auf dem gleichen Konzept des Indexhandlers, um die Abfrage und zuvor indizierte Dokumente abzugleichen. Die Matches werden nach ihrer Angemessenheit oder Relevanz geordnet. Ein kurzes Beispiel für eine Abfrage wird unten gezeigt.
Hochladen von Dokumenten:
Der Einfachheit halber verwenden wir für das folgende Beispiel einen Beispieldatensatz, der bereits von Apache Solr bereitgestellt wird. Das Hochladen von Dokumenten erfolgt als Benutzer solr. Schritt 1 ist die Erstellung eines Kerns mit dem Namen techproducts (für eine Reihe von technischen Artikeln).
$ solr/bin/solr create -c techproducts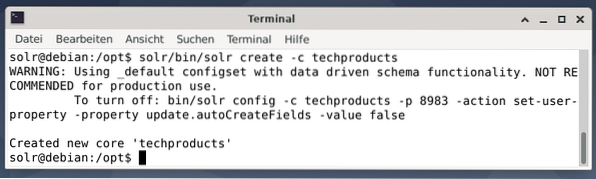
Alles ist in Ordnung, wenn Sie die Meldung „Neuen Kern ‚Techproducts‘ erstellt“ sehen. Schritt 2 ist das Hinzufügen von Daten (XML-Daten aus Beispieldokumenten) zu den zuvor erstellten Kerntechnologieprodukten. Im Einsatz ist der mit -c (Name des Kerns) parametrisierte Toolpost und die hochzuladenden Dokumente.
$ solr/bin/post -c techproducts solr/example/exampledocs/*.xmlDies führt zu der unten gezeigten Ausgabe und enthält den gesamten Aufruf plus die 14 indizierten Dokumente.
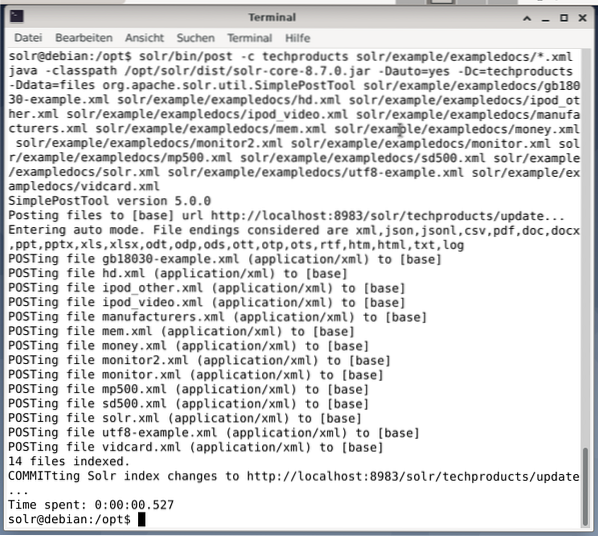
Außerdem zeigt das Dashboard die Änderungen an. Im Dropdown-Menü auf der linken Seite ist ein neuer Eintrag namens techproducts sichtbar, auf der rechten Seite die Anzahl der entsprechenden Dokumente geändert. Eine Detailansicht der Rohdatensätze ist leider nicht möglich.
Falls der Kern/die Sammlung entfernt werden muss, verwenden Sie den folgenden Befehl:
$ solr/bin/solr delete -c techproductsDaten abfragen:
Apache Solr bietet zwei Schnittstellen zum Abfragen von Daten: über das webbasierte Dashboard und die Befehlszeile. Wir werden beide Methoden unten erklären.
Das Senden von Abfragen über das Solr-Dashboard erfolgt wie folgt:
- Wählen Sie den Knoten techproducts aus dem Dropdown-Menü.
- Wählen Sie im Menü unterhalb des Dropdown-Menüs den Eintrag Abfrage.
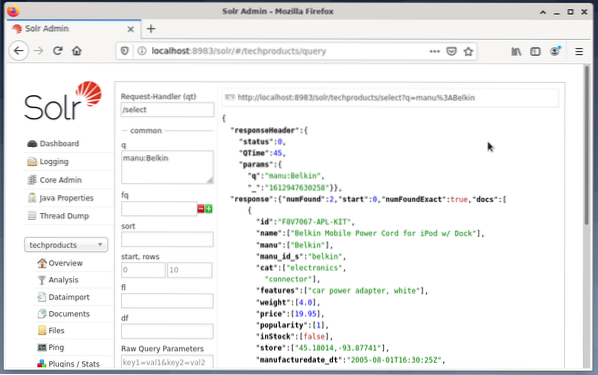
Auf der rechten Seite erscheinen Eingabefelder, um die Abfrage wie Request-Handler (qt), Abfrage (q) und die Sortierreihenfolge (Sort) zu formulieren. - Wählen Sie das Eingabefeld Abfrage und ändern Sie den Inhalt des Eintrags von „*:*“ auf „manu:Belkin“. Dadurch wird die Suche von „alle Felder mit allen Einträgen“ auf „Datensätze, die im Manu-Feld den Namen Belkin haben“ eingeschränkt. In diesem Fall steht im Beispieldatensatz der Name manu für Hersteller.
- Als nächstes drücken Sie die Schaltfläche mit Execute Query. Das Ergebnis ist oben eine gedruckte HTTP-Anfrage und unten ein Ergebnis der Suchanfrage im JSON-Datenformat.
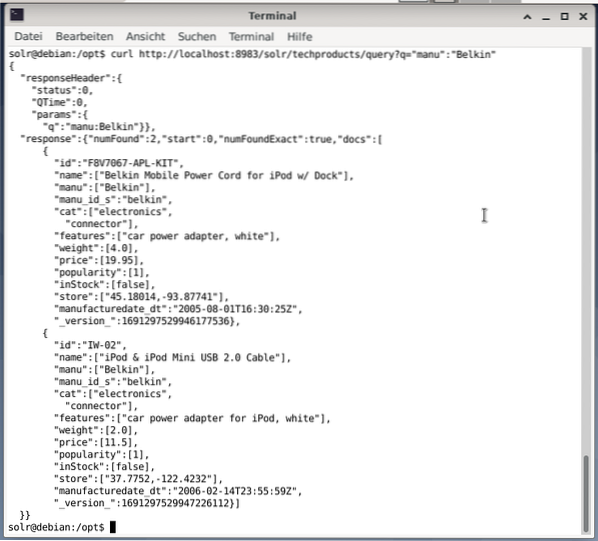
Die Befehlszeile akzeptiert dieselbe Abfrage wie im Dashboard. Der Unterschied besteht darin, dass Sie den Namen der Abfragefelder kennen müssen. Um dieselbe Abfrage wie oben zu senden, müssen Sie den folgenden Befehl in einem Terminal ausführen:
$ curlhttp://localhost:8983/solr/techproducts/query?q=”manu”:”Belkin
Die Ausgabe erfolgt im JSON-Format, wie unten gezeigt. Das Ergebnis besteht aus einem Antwortheader und der eigentlichen Antwort. Die Antwort besteht aus zwei Datensätzen.
Einpacken:
Herzliche Glückwünsche! Sie haben die erste Stufe mit Erfolg erreicht. Die Basisinfrastruktur ist aufgebaut und Sie haben gelernt, Dokumente hochzuladen und abzufragen.
Im nächsten Schritt erfahren Sie, wie Sie die Abfrage verfeinern, komplexere Abfragen formulieren und die verschiedenen Webformulare verstehen, die von der Apache Solr-Abfrageseite bereitgestellt werden. Außerdem werden wir besprechen, wie das Suchergebnis mit verschiedenen Ausgabeformaten wie XML, CSV und JSON nachbearbeitet wird.
Über die Autoren:
Jacqui Kabeta ist Umweltschützerin, begeisterte Forscherin, Trainerin und Mentorin. In mehreren afrikanischen Ländern hat sie in der IT-Branche und im NGO-Umfeld gearbeitet.
Frank Hofmann ist IT-Entwickler, Trainer und Autor und arbeitet am liebsten von Berlin, Genf und Kapstadt aus. Co-Autor des Debian Package Management Book, erhältlich bei dpmbd.org
- [1] Apache Solr, https://lucene.Apache.org/solr/
- [2] Lucene-Suchbibliothek, https://lucene.Apache.Organisation/
- [3]AdvaS Erweiterte Suche, https://pypi.org/project/AdvaS-Advanced-Search/
- [4] Die Top 165 Suchmaschinen-Open-Source-Projekte, https://awesomeopensource.com/projects/search-engine
- [5] ElasticSearch, https://www.elastisch.co/de/elasticsearch/
- [6]Apache Software Foundation (ASF), https://www.Apache.Organisation/
- [7]FESS, https://fess.Codebibliotheken.Organisation/Index.html
- [8] ElasticSearch, https://www.elastisch.Code/
- [9] Apache Solr, Download-Bereich, https://lucene.Apache.org/solr/downloads.htm
- [10] Nvidia V100, https://www.nvidia.com/de-de/rechenzentrum/v100/
- [11] Apache Tika, https://tika.Apache.Organisation/
- [12] Apache Solr-Verzeichnis-Layout, https://lucene.Apache.org/solr/guide/8_8/installing-solr.html#Verzeichnis-Layout
- [13] Wie Suchmaschinen funktionieren: Crawling, Indexierung und Ranking. Der Anfängerleitfaden für SEO https://moz.com/Anfänger-Leitfaden-zu-SEO/wie-Suchmaschinen-Betrieb
- [14] Erste Schritte mit Apache Solr, https://sematext.com/guides/solr/#:~:text=Solr%20works%20by%20gathering%2C%20storing,with%20huge%20volumes%20of%20data


