Angenommen, Sie sind Besitzer eines großen Lebensmittelladens in dem Landkreis, in dem Sie leben. Angenommen, Sie wohnen in einem großen Gebiet, das kein Gewerbegebiet ist. Sie sind nicht der einzige mit einem Lebensmittelladen in der Gegend; Sie haben ein paar Konkurrenten. Und dann fällt Ihnen ein, dass Sie die Telefonnummern Ihrer Kunden in ein Schulheft eintragen sollten. Natürlich ist das Heft klein, und Sie können nicht alle Telefonnummern für alle Ihre Kunden aufnehmen.
Sie beschließen also, nur die Telefonnummern Ihrer Stammkunden aufzuzeichnen. Und so hast du eine Tabelle mit zwei Spalten. Die linke Spalte enthält die Namen der Kunden und die rechte Spalte die entsprechenden Telefonnummern. Auf diese Weise gibt es eine Zuordnung zwischen Kundennamen und Telefonnummern. Die rechte Spalte der Tabelle kann als Kern-Hash-Tabelle betrachtet werden. Kundennamen heißen jetzt Schlüssel, und die Telefonnummern heißen Werte. Beachten Sie, dass Sie bei einer Überweisung eines Kunden seine Zeile stornieren müssen, damit die Zeile leer oder durch die eines neuen Stammkunden ersetzt werden kann. Beachten Sie auch, dass die Anzahl der Stammkunden mit der Zeit zunehmen oder abnehmen kann und der Tisch daher wachsen oder schrumpfen kann.
Nehmen wir als weiteres Beispiel für die Kartierung an, dass es in einem Landkreis einen Bauernklub gibt. Natürlich werden nicht alle Bauern Mitglieder des Clubs sein. Einige Mitglieder des Clubs werden keine ordentlichen Mitglieder sein (Anwesenheit und Beitrag). Der Barkeeper kann beschließen, die Namen der Mitglieder und deren Getränkeauswahl aufzuzeichnen. Er entwickelt eine Tabelle mit zwei Spalten. In die linke Spalte schreibt er die Namen der Vereinsmitglieder. In die rechte Spalte schreibt er die entsprechende Getränkeauswahl.
Hier liegt ein Problem vor: In der rechten Spalte befinden sich Duplikate. Das heißt, der gleiche Name eines Getränks wird mehr als einmal gefunden. Mit anderen Worten, verschiedene Mitglieder trinken dasselbe süße Getränk oder dasselbe alkoholische Getränk, während andere Mitglieder ein anderes süßes oder alkoholisches Getränk trinken. Der Barmann beschließt, dieses Problem zu lösen, indem er eine schmale Spalte zwischen die beiden Spalten einfügt. In dieser mittleren Spalte nummeriert er von oben beginnend die Reihen beginnend bei Null (i.e. 0, 1, 2, 3, 4 usw.), nach unten, ein Index pro Zeile. Damit ist sein Problem gelöst, da ein Mitgliedsname nun einem Index zugeordnet wird und nicht dem Namen eines Getränks. Wenn also ein Getränk durch einen Index identifiziert wird, wird ein Kundenname dem entsprechenden Index zugeordnet.
Allein die Wertespalte (Getränke) bildet die Basis-Hash-Tabelle. In der modifizierten Tabelle bilden die Spalte der Indizes und ihre zugehörigen Werte (mit oder ohne Duplikate) eine normale Hash-Tabelle - die vollständige Definition einer Hash-Tabelle ist unten angegeben. Die Schlüssel (erste Spalte) sind nicht unbedingt Bestandteil der Hash-Tabelle.
Betrachten Sie als weiteres Beispiel einen Netzwerkserver, auf dem ein Benutzer von seinem Client-Computer einige Informationen hinzufügen, einige Informationen löschen oder einige Informationen ändern kann. Es gibt viele Benutzer für den Server. Jeder Benutzername entspricht einem auf dem Server gespeicherten Passwort. Diejenigen, die den Server warten, können die Benutzernamen und das zugehörige Passwort einsehen und können so die Arbeit der Benutzer korrumpieren.
Also beschließt der Besitzer des Servers, eine Funktion zu erstellen, die ein Passwort verschlüsselt, bevor es gespeichert wird. Ein Benutzer meldet sich mit seinem normalen verstandenen Passwort am Server an. Jetzt wird jedoch jedes Passwort in verschlüsselter Form gespeichert. Wenn jemand ein verschlüsseltes Passwort sieht und versucht, sich damit anzumelden, funktioniert es nicht, da beim Anmelden ein vom Server verstandenes Passwort und kein verschlüsseltes Passwort empfangen wird.
In diesem Fall ist das verstandene Passwort der Schlüssel und das verschlüsselte Passwort der Wert. Wenn sich das verschlüsselte Passwort in einer Spalte mit verschlüsselten Passwörtern befindet, ist diese Spalte eine einfache Hash-Tabelle. Wenn dieser Spalte eine andere Spalte mit bei Null beginnenden Indizes vorangeht, so dass jedem verschlüsselten Passwort ein Index zugeordnet ist, dann bilden sowohl die Spalte mit den Indizes als auch die Spalte mit dem verschlüsselten Passwort eine normale Hash-Tabelle. Die Schlüssel sind nicht unbedingt Teil der Hash-Tabelle.
Beachten Sie in diesem Fall, dass jeder Schlüssel, der ein verstandenes Passwort ist, einem Benutzernamen entspricht. Es gibt also einen Benutzernamen, der einem Schlüssel entspricht, der einem Index zugeordnet ist, der einem Wert zugeordnet ist, der ein verschlüsselter Schlüssel ist.
Die Definition einer Hash-Funktion, die vollständige Definition einer Hash-Tabelle, die Bedeutung eines Arrays und andere Details sind unten aufgeführt. Sie müssen über Kenntnisse in Zeigern (Referenzen) und verknüpften Listen verfügen, um den Rest dieses Tutorials zu verstehen.
Bedeutung von Hash-Funktion und Hash-Tabelle
Array
Ein Array ist ein Satz aufeinanderfolgender Speicherorte. Alle Standorte haben die gleiche Größe. Auf den Wert an der ersten Stelle wird mit dem Index 0 zugegriffen; auf den Wert an der zweiten Stelle wird mit dem Index 1 zugegriffen; auf den dritten Wert wird mit dem Index 2 zugegriffen; vierte mit Index, 3; und so weiter. Ein Array kann normalerweise nicht vergrößert oder verkleinert werden. Um die Größe (Länge) eines Arrays zu ändern, muss ein neues Array erstellt und die entsprechenden Werte in das neue Array kopiert werden. Die Werte eines Arrays sind immer vom gleichen Typ.
Hash-Funktion
In der Software ist eine Hash-Funktion eine Funktion, die einen Schlüssel nimmt und einen entsprechenden Index für eine Array-Zelle erzeugt. Das Array hat eine feste Größe (feste Länge). Die Anzahl der Schlüssel ist beliebig groß, normalerweise größer als die Größe des Arrays. Der aus der Hash-Funktion resultierende Index heißt Hash-Wert oder Digest oder Hash-Code oder einfach Hash.
Hash-tabelle
Eine Hashtabelle ist ein Array mit Werten, auf deren Indizes Schlüssel abgebildet werden. Die Schlüssel werden den Werten indirekt zugeordnet. Tatsächlich werden die Schlüssel den Werten zugeordnet, da jedem Index ein Wert zugeordnet ist (mit oder ohne Duplikate). Die Funktion, die das Mapping durchführt (i.e. Hashing) verknüpft Schlüssel mit den Array-Indizes und nicht wirklich mit den Werten, da es in den Werten Duplikate geben könnte. Das folgende Diagramm zeigt eine Hash-Tabelle für die Namen von Personen und ihre Telefonnummern. Die Array-Zellen (Slots) werden als Buckets bezeichnet.
Beachten Sie, dass einige Eimer leer sind. Eine Hashtabelle muss nicht unbedingt in allen Buckets Werte enthalten. Die Werte in den Buckets müssen nicht unbedingt aufsteigend sein. Die Indizes, mit denen sie verknüpft sind, sind jedoch in aufsteigender Reihenfolge. Die Pfeile zeigen die Zuordnung an. Beachten Sie, dass sich die Schlüssel nicht in einem Array befinden. Sie müssen in keiner Struktur sein. Eine Hash-Funktion nimmt einen beliebigen Schlüssel und hasht einen Index für ein Array aus. Wenn der mit dem Index-Hashing verknüpfte Bucket keinen Wert enthält, kann ein neuer Wert in diesen Bucket eingefügt werden. Die logische Beziehung besteht zwischen dem Schlüssel und dem Index und nicht zwischen dem Schlüssel und dem mit dem Index verknüpften Wert.
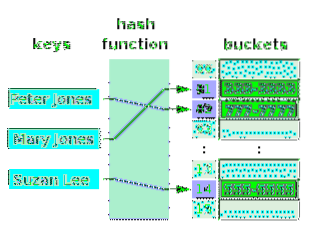
Die Werte eines Arrays, wie die dieser Hash-Tabelle, sind immer vom gleichen Datentyp. Eine Hash-Tabelle (Buckets) kann Schlüssel mit den Werten verschiedener Datentypen verbinden. In diesem Fall sind die Werte des Arrays alle Zeiger, die auf verschiedene Werttypen zeigen.
Eine Hash-Tabelle ist ein Array mit einer Hash-Funktion. Die Funktion nimmt einen Schlüssel und hasht einen entsprechenden Index und verbindet so Schlüssel mit Werten im Array. Die Schlüssel müssen nicht Teil der Hash-Tabelle sein.
Warum Array und nicht verknüpfte Liste für Hash-Tabelle?
Das Array für eine Hash-Tabelle kann durch eine Linked-List-Datenstruktur ersetzt werden, aber es würde ein Problem geben. Das erste Element einer verknüpften Liste befindet sich natürlich bei Index 0; das zweite Element ist natürlich bei Index 1; der dritte ist natürlich bei Index 2; und so weiter. Das Problem mit der verknüpften Liste besteht darin, dass zum Abrufen eines Werts die Liste durchlaufen werden muss, und dies braucht Zeit takes. Der Zugriff auf einen Wert in einem Array erfolgt durch wahlfreien Zugriff. Sobald der Index bekannt ist, wird der Wert ohne Iteration ermittelt; dieser Zugriff ist schneller.
Kollision
Die Hash-Funktion nimmt einen Schlüssel und hasht den entsprechenden Index, um den zugehörigen Wert zu lesen oder einen neuen Wert einzufügen. Wenn der Zweck darin besteht, einen Wert zu lesen, gibt es bisher kein Problem (kein Problem). Wenn jedoch ein Wert eingefügt werden soll, hat der Hash-Index möglicherweise bereits einen zugehörigen Wert, und das ist eine Kollision; der neue Wert kann nicht dort eingefügt werden, wo bereits ein Wert vorhanden ist. Es gibt Möglichkeiten, Kollisionen zu lösen - siehe unten.
Warum es zu Kollisionen kommt
Im obigen Beispiel eines Proviantshops sind die Kundennamen die Schlüssel und die Namen der Getränke die Werte. Beachten Sie, dass es zu viele Kunden gibt, während das Array eine begrenzte Größe hat und nicht alle Kunden aufnehmen kann. Es werden also nur die Getränke von Stammkunden im Array gespeichert. Die Kollision würde auftreten, wenn ein nicht regelmäßiger Kunde zu einem regelmäßigen Kunden wird. Kunden für den Shop bilden ein großes Set, während die Anzahl der Eimer für Kunden im Array begrenzt ist.
Bei Hash-Tabellen werden die Werte der Schlüssel mit hoher Wahrscheinlichkeit aufgezeichnet. Wenn ein Schlüssel, der unwahrscheinlich war, wahrscheinlich wird, würde es wahrscheinlich zu einer Kollision kommen. Tatsächlich kommt es bei Hash-Tabellen immer zu Kollisionen.
Grundlagen der Kollisionsauflösung
Zwei Ansätze zur Kollisionsauflösung werden als separate Verkettung und offene Adressierung bezeichnet. Theoretisch sollten die Schlüssel nicht in der Datenstruktur oder nicht Teil der Hash-Tabelle sein. Beide Ansätze erfordern jedoch, dass die Schlüsselspalte der Hash-Tabelle vorangeht und Teil der Gesamtstruktur wird. Anstelle von Schlüsseln in der Schlüsselspalte können sich Zeiger auf die Schlüssel in der Schlüsselspalte befinden.
Eine praktische Hash-Tabelle enthält eine Schlüsselspalte, aber diese Schlüsselspalte ist nicht offiziell Teil der Hash-Tabelle.
Jeder Lösungsansatz kann leere Buckets haben, nicht unbedingt am Ende des Arrays.
Separate Verkettung
Bei einer separaten Verkettung wird bei einer Kollision der neue Wert rechts (nicht oberhalb oder unterhalb) des kollidierten Werts hinzugefügt. Am Ende haben also zwei oder drei Werte den gleichen Index. Selten sollten mehr als drei den gleichen Index haben.
Können mehrere Werte in einem Array wirklich denselben Index haben?? - Nein. In vielen Fällen ist der erste Wert für den Index also ein Zeiger auf eine Linked-List-Datenstruktur, die einen, zwei oder drei kollidierte Werte enthält holds. Das folgende Diagramm ist ein Beispiel für eine Hash-Tabelle zur getrennten Verkettung von Kunden und deren Telefonnummern:
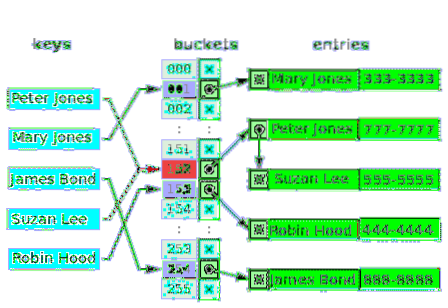
Die leeren Eimer sind mit dem Buchstaben x . gekennzeichnet. Der Rest der Slots hat Zeiger auf verknüpfte Listen. Jedes Element der verknüpften Liste hat zwei Datenfelder: eines für den Kundennamen und das andere für die Telefonnummer. Es kommt zu Konflikten um die Schlüssel: Peter Jones und Suzan Lee. Die entsprechenden Werte bestehen aus zwei Elementen einer verketteten Liste.
Bei widersprüchlichen Schlüsseln ist das Kriterium zum Einfügen von Werten dasselbe Kriterium, das verwendet wird, um den Wert zu finden (und zu lesen).
Offene Adressierung
Bei offener Adressierung werden alle Werte im Bucket-Array gespeichert. Wenn ein Konflikt auftritt, wird der neue Wert nach einem bestimmten Kriterium in einen leeren Bucket neu den entsprechenden Wert für den Konflikt eingefügt. Das Kriterium, das verwendet wird, um einen Wert bei Konflikt einzufügen, ist das gleiche Kriterium, das verwendet wird, um den Wert zu lokalisieren (zu suchen und zu lesen).
Das folgende Diagramm veranschaulicht die Konfliktlösung mit offener Adressierung:
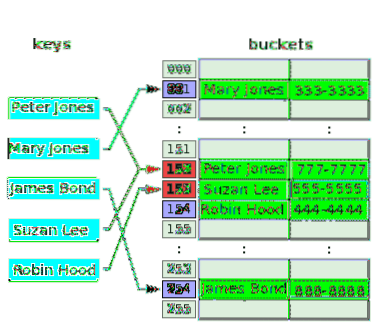 Die Hash-Funktion nimmt den Schlüssel Peter Jones und hasht den Index 152 und speichert seine Telefonnummer im zugehörigen Bucket. Nach einiger Zeit hasht die Hash-Funktion denselben Index, 152 aus dem Schlüssel Suzan Lee, was mit dem Index für Peter Jones kollidiert. Um dies zu beheben, wird der Wert für Suzan Lee im Bucket des nächsten Index, 153, gespeichert, der leer war. Die Hash-Funktion hasht den Index, 153 für den Schlüssel Robin Hood, aber dieser Index wurde bereits verwendet, um den Konflikt für einen vorherigen Schlüssel zu lösen. Der Wert für Robin Hood wird also in den nächsten leeren Bucket gelegt, der dem Index 154 entspricht.
Die Hash-Funktion nimmt den Schlüssel Peter Jones und hasht den Index 152 und speichert seine Telefonnummer im zugehörigen Bucket. Nach einiger Zeit hasht die Hash-Funktion denselben Index, 152 aus dem Schlüssel Suzan Lee, was mit dem Index für Peter Jones kollidiert. Um dies zu beheben, wird der Wert für Suzan Lee im Bucket des nächsten Index, 153, gespeichert, der leer war. Die Hash-Funktion hasht den Index, 153 für den Schlüssel Robin Hood, aber dieser Index wurde bereits verwendet, um den Konflikt für einen vorherigen Schlüssel zu lösen. Der Wert für Robin Hood wird also in den nächsten leeren Bucket gelegt, der dem Index 154 entspricht.
Methoden zur Konfliktlösung für getrennte Verkettung und offene Adressierung
Die separate Verkettung hat ihre eigenen Methoden zur Konfliktlösung, und die offene Adressierung hat auch ihre eigenen Methoden zur Konfliktlösung.
Methoden zur Lösung separater Verkettungskonflikte
Die Methoden zum separaten Verketten von Hash-Tabellen werden nun kurz erklärt:
Separate Verkettung mit verknüpften Listen
Diese Methode ist wie oben erklärt. Allerdings muss nicht jedes Element der verketteten Liste zwingend das Schlüsselfeld (z.G. Feld Kundenname oben).
Separate Verkettung mit Listenkopfzellen
Bei dieser Methode wird das erste Element der verknüpften Liste in einem Bucket des Arrays gespeichert. Dies ist möglich, wenn der Datentyp für das Array das Element der verknüpften Liste ist.
Separate Verkettung mit anderen Strukturen
Anstelle der verknüpften Liste kann jede andere Datenstruktur verwendet werden, z. B. der selbstausgleichende binäre Suchbaum, der die erforderlichen Operationen unterstützt - siehe später.
Methoden zur Lösung von offenen Adressierungskonflikten
Eine Methode zum Auflösen von Konflikten bei der offenen Adressierung wird als Sondensequenz bezeichnet. Drei bekannte Sondensequenzen werden nun kurz erläutert:
Lineare Sondierung
Bei der linearen Sondierung wird beim Auftreten eines Konflikts nach dem nächsten leeren Bucket unter dem Bucket bei Konflikt gesucht. Außerdem werden bei der linearen Sondierung sowohl der Schlüssel als auch sein Wert im selben Bucket gespeichert.
Quadratische Sondierung
Angenommen, ein Konflikt tritt bei Index H . auf. Der nächste leere Slot (Bucket) bei Index H + 12 wird eingesetzt; wenn dieser schon belegt ist, dann der nächste leere bei H + 22 wird verwendet, wenn dieser schon belegt ist, dann der nächste leere bei H + 32 verwendet wird und so weiter. Dazu gibt es Varianten.
Doppel-Hashing
Beim Double Hashing gibt es zwei Hashfunktionen. Der erste berechnet (hasht) den Index. Wenn ein Konflikt auftritt, verwendet der zweite den gleichen Schlüssel, um zu bestimmen, wie weit unten der Wert eingefügt werden soll. Es gibt noch mehr dazu - siehe später.
Perfekte Hash-Funktion
Eine perfekte Hash-Funktion ist eine Hash-Funktion, die zu keiner Kollision führen kann. Dies kann passieren, wenn der Schlüsselsatz relativ klein ist und jeder Schlüssel einer bestimmten Ganzzahl in der Hash-Tabelle zugeordnet ist.
Im ASCII-Zeichensatz können Großbuchstaben mithilfe einer Hash-Funktion den entsprechenden Kleinbuchstaben zugeordnet werden. Buchstaben werden im Computerspeicher als Zahlen dargestellt. Im ASCII-Zeichensatz ist A 65, B ist 66, C ist 67 usw. und a ist 97, b ist 98, c ist 99 usw. Um von A nach a abzubilden, addieren Sie 32 zu 65; um von B nach b abzubilden, addiere 32 zu 66; um von C nach c abzubilden, addiere 32 zu 67; und so weiter. Hier sind die Großbuchstaben die Tasten und die Kleinbuchstaben die Werte. Die Hash-Tabelle dafür kann ein Array sein, dessen Werte die zugehörigen Indizes sind. Denken Sie daran, dass Eimer des Arrays leer sein können. Buckets im Array von 64 bis 0 können also leer sein. Die Hash-Funktion addiert einfach 32 zur Großbuchstaben-Codenummer, um den Index und damit den Kleinbuchstaben zu erhalten. Eine solche Funktion ist eine perfekte Hash-Funktion.
Hashing von Integer zu Integer Indizes
Es gibt verschiedene Methoden für das Hashing ganzer Zahlen. Eine davon heißt Modulo Division Method (Funktion).
Die Modulo Division Hashing-Funktion
Eine Funktion in Computersoftware ist keine mathematische Funktion. In der Informatik (Software) besteht eine Funktion aus einer Menge von Anweisungen, denen Argumente vorangestellt sind. Für die Modulo-Divisionsfunktion sind die Schlüssel ganze Zahlen und werden auf Indizes des Arrays von Buckets abgebildet. Der Schlüsselsatz ist groß, sodass nur Schlüssel zugeordnet werden, die mit hoher Wahrscheinlichkeit in der Aktivität vorkommen. Es kommt also zu Kollisionen, wenn unwahrscheinliche Schlüssel zugeordnet werden müssen.
In der Aussage,
20 / 6 = 3R2
20 ist der Dividende, 6 ist der Divisor und 3 Rest 2 ist der Quotient. Der Rest 2 heißt auch modulo. Hinweis: Es ist möglich, einen Modulo von 0 . zu haben.
Für dieses Hashing ist die Tabellengröße normalerweise eine Potenz von 2, e.G. 64 = 26 oder 256 = 28, usw. Der Divisor für diese Hashing-Funktion ist eine Primzahl nahe der Array-Größe. Diese Funktion dividiert den Schlüssel durch den Divisor und gibt das Modulo . zurück. Das Modulo ist der Index des Arrays von Buckets. Der zugehörige Wert im Bucket ist ein Wert Ihrer Wahl (Wert für den Schlüssel).
Hashing von Schlüsseln mit variabler Länge
Hier sind die Tasten des Tastensatzes Texte unterschiedlicher Länge. Verschiedene Ganzzahlen können mit der gleichen Anzahl von Bytes im Speicher gespeichert werden (die Größe eines englischen Zeichens ist ein Byte). Wenn verschiedene Schlüssel unterschiedliche Byte-Größen haben, spricht man von variabler Länge. Eine der Methoden zum Hashing variabler Längen wird Radix Conversion Hashing genannt.
Radix Conversion Hashing
In einer Zeichenfolge ist jedes Zeichen im Computer eine Zahl. Bei dieser Methode,
Hash-Code (Index) = x0eink−1+x1eink−2+… +xk−2ein1+xk−1ein0
Wobei (x0, x1,… , xk−1) die Zeichen des Eingabestrings sind und a ein Radix ist, e.G. 29 (siehe später). k ist die Anzahl der Zeichen in der Zeichenfolge. Es gibt noch mehr dazu - siehe später.
Schlüssel und Werte
In einem Schlüssel/Wert-Paar muss ein Wert nicht unbedingt eine Zahl oder ein Text sein. Es kann auch ein Rekord sein. Ein Datensatz ist eine horizontal geschriebene Liste. In einem Schlüssel/Wert-Paar kann sich jeder Schlüssel tatsächlich auf einen anderen Text oder eine andere Zahl oder einen anderen Datensatz beziehen.
Assoziatives Array
Eine Liste ist eine Datenstruktur, in der die Listenelemente miteinander verknüpft sind, und es gibt eine Reihe von Operationen, die auf die Liste angewendet werden. Jedes Listenelement kann aus einem Paar von Elementen bestehen. Die allgemeine Hash-Tabelle mit ihren Schlüsseln kann als Datenstruktur betrachtet werden, ist aber eher ein System als eine Datenstruktur. Die Schlüssel und ihre entsprechenden Werte sind nicht sehr voneinander abhängig. Sie sind nicht sehr verwandt.
Auf der anderen Seite ist ein assoziatives Array ähnlich, aber Schlüssel und ihre Werte hängen stark voneinander ab; sie sind sehr verwandt. Zum Beispiel können Sie eine assoziative Reihe von Früchten und deren Farben haben. Jede Frucht hat von Natur aus ihre Farbe. Der Name der Frucht ist der Schlüssel; die farbe ist der wert. Beim Einfügen wird jeder Schlüssel mit seinem Wert eingefügt. Beim Löschen wird jeder Schlüssel mit seinem Wert gelöscht.
Ein assoziatives Array ist eine Hash-Tabellen-Datenstruktur, die aus Schlüssel/Wert-Paaren besteht, wobei es keine Duplikate für die Schlüssel gibt. Die Werte können Duplikate haben. In dieser Situation sind die Schlüssel Teil der Struktur. Das heißt, die Schlüssel müssen gespeichert werden, während bei der allgemeinen Hast-Tabelle die Schlüssel nicht gespeichert werden müssen. Das Problem der duplizierten Werte wird natürlich durch die Indizes des Arrays von Buckets gelöst. Verwechseln Sie nicht zwischen doppelten Werten und Kollisionen bei einem Index.
Da ein assoziatives Array eine Datenstruktur ist, hat es mindestens die folgenden Operationen:
Assoziative Array-Operationen
einfügen oder hinzufügen
Dadurch wird ein neues Schlüssel/Wert-Paar in die Sammlung eingefügt und der Schlüssel seinem Wert zugeordnet.
neu zuweisen
Diese Operation ersetzt den Wert eines bestimmten Schlüssels durch einen neuen Wert.
löschen oder entfernen
Dies entfernt einen Schlüssel plus seinen entsprechenden Wert.
Nachschlagen
Diese Operation sucht nach dem Wert eines bestimmten Schlüssels und gibt den Wert zurück (ohne ihn zu entfernen).
Fazit
Eine Hash-Tabellen-Datenstruktur besteht aus einem Array und einer Funktion. Die Funktion heißt Hash-Funktion. Die Funktion ordnet Schlüssel Werten im Array über die Indizes des Arrays zu. Die Schlüssel müssen nicht unbedingt Teil der Datenstruktur sein. Der Schlüsselsatz ist in der Regel größer als die gespeicherten Werte. Wenn eine Kollision auftritt, wird sie entweder durch den separaten Verkettungsansatz oder den offenen Adressierungsansatz gelöst Address. Ein assoziatives Array ist ein Sonderfall der Hash-Tabellen-Datenstruktur.


