Bevor Sie die Pivot-Tabelle von Panda verwenden, stellen Sie sicher, dass Sie Ihre Daten und Fragen verstehen, die Sie mit der Pivot-Tabelle lösen möchten. Mit dieser Methode können Sie starke Ergebnisse erzielen. Wir werden in diesem Artikel erläutern, wie man eine Pivot-Tabelle in Pandas Python erstellt.
Daten aus Excel-Datei lesen
Wir haben eine Excel-Datenbank mit Lebensmittelverkäufen heruntergeladen. Bevor Sie mit der Implementierung beginnen, müssen Sie einige erforderliche Pakete zum Lesen und Schreiben der Excel-Datenbankdateien installieren. Geben Sie den folgenden Befehl in den Terminalbereich Ihres pycharm-Editors ein:
pip install xlwt openpyxl xlsxwriter xlrd
Lesen Sie nun die Daten aus dem Excel-Blatt. Importieren Sie die erforderlichen Panda-Bibliotheken und ändern Sie den Pfad Ihrer Datenbank. Durch Ausführen des folgenden Codes können dann Daten aus der Datei abgerufen werden.
Pandas als pd importierennumpy als np importieren
dtfrm = pd.read_excel('C:/Users/DELL/Desktop/foodsalesdata.xlsx')
drucken (dtfrm)
Hier werden die Daten aus der Excel-Datenbank des Lebensmittelverkaufs gelesen und an die Datenrahmenvariable übergeben.
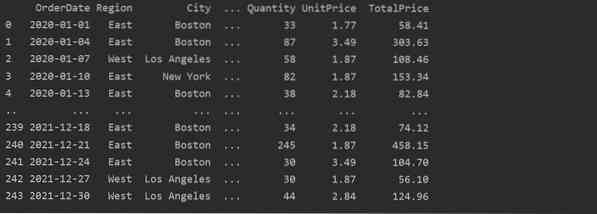
Erstellen Sie eine Pivot-Tabelle mit Pandas Python
Unten haben wir eine einfache Pivot-Tabelle erstellt, indem wir die Lebensmittelverkaufsdatenbank verwenden. Zum Erstellen einer Pivot-Tabelle sind zwei Parameter erforderlich. Das erste sind Daten, die wir an den Datenrahmen übergeben haben, und das andere ist ein Index.
Pivot-Daten auf einem Index
Der Index ist die Funktion einer Pivot-Tabelle, mit der Sie Ihre Daten nach Anforderungen gruppieren können. Hier haben wir 'Produkt' als Index genommen, um eine einfache Pivot-Tabelle zu erstellen.
Pandas als pd importierennumpy als np importieren
Datenrahmen = pd.read_excel('C:/Users/DELL/Desktop/foodsalesdata.xlsx')
pivot_tble=pd.pivot_table(dataframe,index=["Produkt"])
print(pivot_tble)
Das folgende Ergebnis zeigt nach dem Ausführen des obigen Quellcodes:
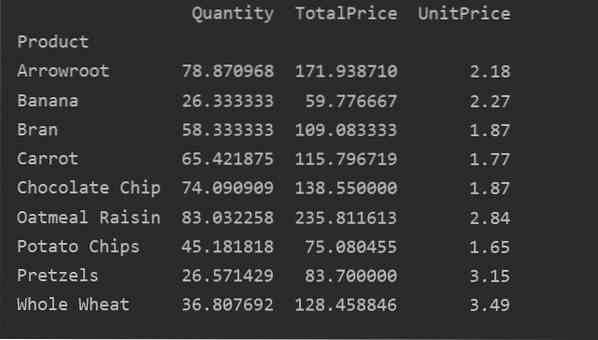
Spalten explizit definieren
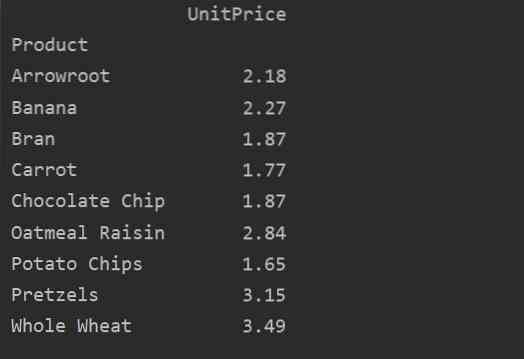
Für eine genauere Analyse Ihrer Daten definieren Sie die Spaltennamen explizit mit dem Index. Zum Beispiel möchten wir den einzigen Einheitspreis jedes Produkts im Ergebnis anzeigen. Fügen Sie dazu den Parameter values in Ihre Pivot-Tabelle ein. Der folgende Code liefert das gleiche Ergebnis:
Pandas als pd importierennumpy als np importieren
Datenrahmen = pd.read_excel('C:/Users/DELL/Desktop/foodsalesdata.xlsx')
pivot_tble=pd.pivot_table(dataframe, index='Product', values='UnitPrice')
print(pivot_tble)
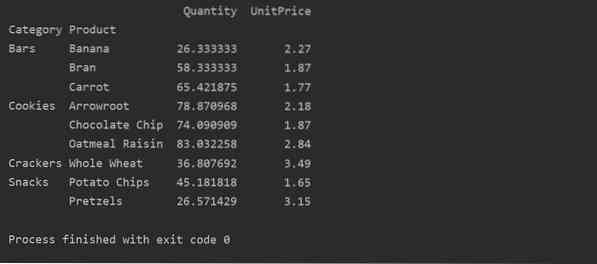
Pivot-Daten mit Multi-Index
Daten können basierend auf mehr als einem Merkmal als Index gruppiert werden. Durch die Verwendung des Multi-Index-Ansatzes können Sie spezifischere Ergebnisse für die Datenanalyse erhalten. Zum Beispiel fallen Produkte in verschiedene Kategorien. So können Sie den 'Produkt'- und 'Kategorie'-Index mit verfügbarer 'Menge' und 'Stückpreis' jedes Produkts wie folgt anzeigen:
Pandas als pd importierennumpy als np importieren
Datenrahmen = pd.read_excel('C:/Users/DELL/Desktop/foodsalesdata.xlsx')
pivot_tble=pd.pivot_table(dataframe,index=["Category","Product"],values=["UnitPrice", "Quantity"])
print(pivot_tble)
Anwenden der Aggregationsfunktion in der Pivot-Tabelle
In einer Pivot-Tabelle kann die aggfunc auf verschiedene Merkmalswerte angewendet werden. Die resultierende Tabelle ist die Zusammenfassung der Merkmalsdaten. Die Aggregatfunktion gilt für Ihre Gruppendaten in pivot_table. Standardmäßig ist die Aggregatfunktion np.bedeuten(). Je nach Benutzeranforderungen können jedoch unterschiedliche Aggregatfunktionen für unterschiedliche Datenmerkmale gelten.
Beispiel:
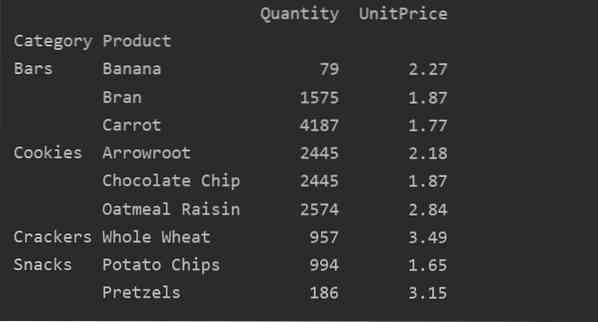
In diesem Beispiel haben wir Aggregatfunktionen angewendet. Die np.Die Funktion sum() wird für die Funktion 'Menge' und np . verwendet.mean()-Funktion für 'UnitPrice'-Funktion.
Pandas als pd importierennumpy als np importieren
Datenrahmen = pd.read_excel('C:/Users/DELL/Desktop/foodsalesdata.xlsx')
pivot_tble=pd.pivot_table(dataframe,index=["Category","Product"], aggfunc='Quantity': np.Summe,'Einheitspreis': np.bedeuten)
print(pivot_tble)
Nachdem Sie die Aggregationsfunktion für verschiedene Features angewendet haben, erhalten Sie die folgende Ausgabe:
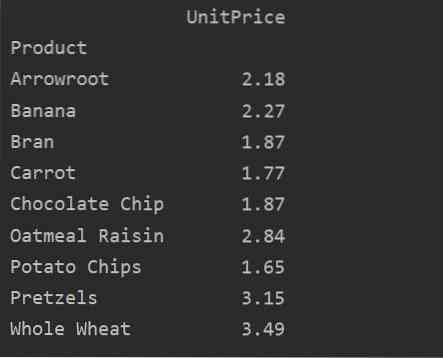
Mit dem Wertparameter können Sie auch die Aggregatfunktion für ein bestimmtes Merkmal anwenden. Wenn Sie den Wert des Merkmals nicht angeben, werden die numerischen Merkmale Ihrer Datenbank aggregiert. Indem Sie dem angegebenen Quellcode folgen, können Sie die Aggregatfunktion für ein bestimmtes Feature anwenden:
Pandas als pd importierennumpy als np importieren
Datenrahmen = pd.read_excel('C:/Users/DELL/Desktop/foodsalesdata.xlsx')
pivot_tble=pd.pivot_table(dataframe, index=['Product'], values=['UnitPrice'], aggfunc=np.bedeuten)
print(pivot_tble)
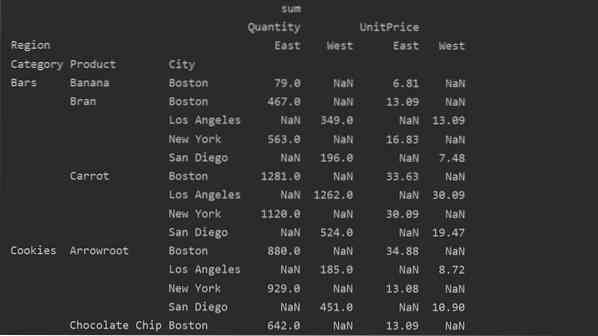
Unterschied zwischen Werten vs. Spalten in der Pivot-Tabelle
Die Werte und Spalten sind der Hauptverwirrungspunkt in der pivot_table. Es ist wichtig zu beachten, dass Spalten optionale Felder sind, in denen die Werte der resultierenden Tabelle horizontal oben angezeigt werden. Die Aggregationsfunktion aggfunc gilt für das Wertefeld, das Sie auflisten.
Pandas als pd importierennumpy als np importieren
Datenrahmen = pd.read_excel('C:/Users/DELL/Desktop/foodsalesdata.xlsx')
pivot_tble=pd.pivot_table(dataframe,index=['Kategorie','Produkt', 'Stadt'],values=['Einheitspreis', 'Menge'],
Spalten=['Region'],aggfunc=[np.Summe])
print(pivot_tble)
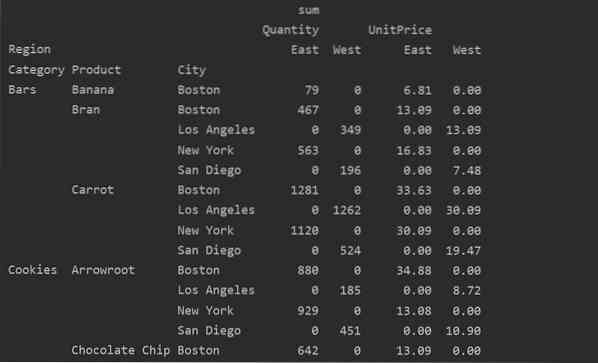
Umgang mit fehlenden Daten in der Pivot-Tabelle
Sie können die fehlenden Werte in der Pivot-Tabelle auch behandeln, indem Sie die 'fill_value' Parameter. Auf diese Weise können Sie die NaN-Werte durch einen neuen Wert ersetzen, den Sie zum Ausfüllen bereitstellen.
Zum Beispiel haben wir alle Nullwerte aus der obigen resultierenden Tabelle entfernt, indem wir den folgenden Code ausgeführt haben und die NaN-Werte in der gesamten resultierenden Tabelle durch 0 ersetzt haben.
Pandas als pd importierennumpy als np importieren
Datenrahmen = pd.read_excel('C:/Users/DELL/Desktop/foodsalesdata.xlsx')
pivot_tble=pd.pivot_table(dataframe,index=['Kategorie','Produkt', 'Stadt'],values=['Einheitspreis', 'Menge'],
Spalten=['Region'],aggfunc=[np.Summe], fill_value=0)
print(pivot_tble)
Filtern in der Pivot-Tabelle
Sobald das Ergebnis generiert wurde, können Sie den Filter mithilfe der Standard-Datenrahmenfunktion anwenden. Nehmen wir ein Beispiel. Filtern Sie die Produkte, deren Einzelpreis weniger als 60 . beträgt. Es zeigt die Produkte an, deren Preis weniger als 60 . beträgt.
Pandas als pd importierennumpy als np importieren
Datenrahmen = pd.read_excel('C:/Users/DELL/Desktop/foodsalesdata.xlsx', index_col=0)
pivot_tble=pd.pivot_table(dataframe, index='Product', values='UnitPrice', aggfunc='sum')
low_price=pivot_tble[pivot_tble['Einheitspreis'] < 60]
drucken (niedriger_preis)

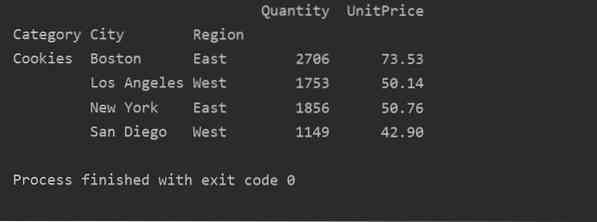
Durch die Verwendung einer anderen Abfragemethode können Sie die Ergebnisse filtern. Wir haben beispielsweise die Kategorie Cookies basierend auf den folgenden Merkmalen gefiltert:
Pandas als pd importierennumpy als np importieren
Datenrahmen = pd.read_excel('C:/Users/DELL/Desktop/foodsalesdata.xlsx', index_col=0)
pivot_tble=pd.pivot_table(dataframe,index=["Category","City","Region"],values=["UnitPrice", "Quantity"],aggfunc=np.Summe)
pt=pivot_tble.query('Kategorie == ["Cookies"]')
drucken (pt)
Ausgabe:
Visualisieren Sie die Pivot-Tabellendaten
Gehen Sie wie folgt vor, um die Pivot-Tabellendaten zu visualisieren:
Pandas als pd importierennumpy als np importieren
Matplotlib importieren.pyplot als plt
Datenrahmen = pd.read_excel('C:/Users/DELL/Desktop/foodsalesdata.xlsx', index_col=0)
pivot_tble=pd.pivot_table(dataframe,index=["Kategorie","Produkt"],values=["Einheitspreis"])
Pivot_Tble.plot(kind='bar');
plt.Show()
In der obigen Visualisierung haben wir den Stückpreis der verschiedenen Produkte zusammen mit Kategorien angezeigt.

Fazit
Wir haben untersucht, wie Sie mit Pandas Python eine Pivot-Tabelle aus dem Datenrahmen generieren können. Mit einer Pivot-Tabelle können Sie tiefe Einblicke in Ihre Datensätze gewinnen. Wir haben gesehen, wie man eine einfache Pivot-Tabelle mit Multi-Index generiert und die Filter auf Pivot-Tabellen anwendet. Darüber hinaus haben wir auch gezeigt, dass Pivot-Tabellendaten geplottet und fehlende Daten ausgefüllt werden können.


