Apache Spark ist ein Datenanalysetool, mit dem Daten aus HDFS, S3 oder anderen Datenquellen im Speicher verarbeitet werden können. In diesem Beitrag installieren wir Apache Spark auf einem Ubuntu 17.10 Maschine.
Ubuntu-Version
Für diese Anleitung verwenden wir Ubuntu Version 17.10 (GNU/Linux 4.13.0-38-generisch x86_64).
Apache Spark ist Teil des Hadoop-Ökosystems für Big Data. Versuchen Sie, Apache Hadoop zu installieren und eine Beispielanwendung damit zu erstellen.
Aktualisieren vorhandener Pakete
Um die Installation für Spark zu starten, müssen wir unseren Computer mit den neuesten verfügbaren Softwarepaketen aktualisieren. Wir können dies tun mit:
sudo apt-get update && sudo apt-get -y dist-upgradeDa Spark auf Java basiert, müssen wir es auf unserem Computer installieren. Wir können jede Java-Version über Java 6 verwenden. Hier verwenden wir Java 8:
sudo apt-get -y install openjdk-8-jdk-headlessHerunterladen von Spark-Dateien
Alle notwendigen Pakete sind jetzt auf unserer Maschine vorhanden. Wir sind bereit, die erforderlichen Spark-TAR-Dateien herunterzuladen, damit wir sie einrichten und auch ein Beispielprogramm mit Spark ausführen können.
In dieser Anleitung installieren wir Funke v2.3.0 hier verfügbar:
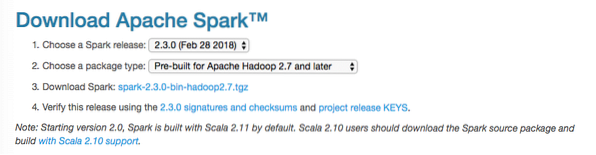
Spark-Downloadseite
Laden Sie die entsprechenden Dateien mit diesem Befehl herunter:
wget http://www-us.Apache.org/dist/spark/spark-2.3.0/Funke-2.3.0-bin-hadoop2.7.tgzJe nach Netzwerkgeschwindigkeit kann dies einige Minuten dauern, da die Datei groß ist:
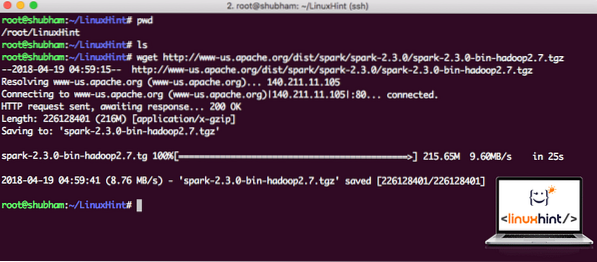
Herunterladen von Apache Spark
Nachdem wir die TAR-Datei heruntergeladen haben, können wir sie in das aktuelle Verzeichnis extrahieren:
tar xvzf Funke-2.3.0-bin-hadoop2.7.tgzDies dauert aufgrund der großen Dateigröße des Archivs einige Sekunden:
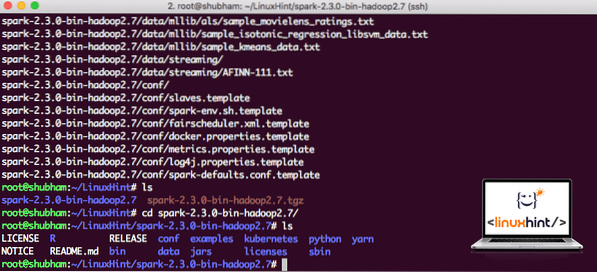
Nicht archivierte Dateien in Spark
Wenn es darum geht, Apache Spark in Zukunft zu aktualisieren, kann es aufgrund von Path-Updates zu Problemen kommen. Diese Probleme können vermieden werden, indem ein Softlink zu Spark erstellt wird. Führen Sie diesen Befehl aus, um einen Softlink zu erstellen:
ln -s Funke-2.3.0-bin-hadoop2.7 FunkenHinzufügen von Funken zum Pfad
Um Spark-Skripte auszuführen, fügen wir es jetzt zum Pfad hinzu. Öffnen Sie dazu die bashrc-Datei:
vi ~/.bashrcFüge diese Zeilen an das Ende des .bashrc-Datei, sodass der Pfad den Pfad der ausführbaren Spark-Datei enthalten kann:
SPARK_HOME=/LinuxHint/sparkexport PATH=$SPARK_HOME/bin:$PATH
Nun sieht die Datei so aus:
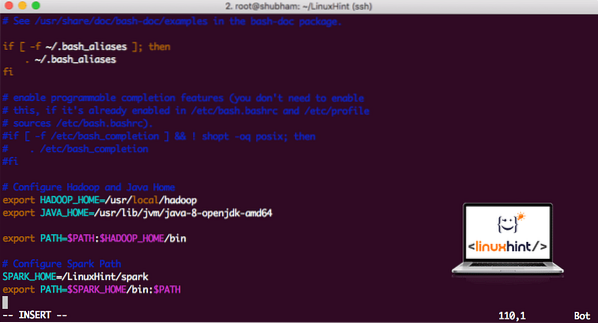
Hinzufügen von Funken zu PATH
Um diese Änderungen zu aktivieren, führen Sie den folgenden Befehl für die bashrc-Datei aus:
Quelle ~/.bashrcSpark Shell starten
Wenn wir uns jetzt direkt außerhalb des Spark-Verzeichnisses befinden, führen Sie den folgenden Befehl aus, um die apark-Shell zu öffnen:
./spark/bin/spark-shellWir werden sehen, dass die Spark-Shell jetzt geöffnet ist:
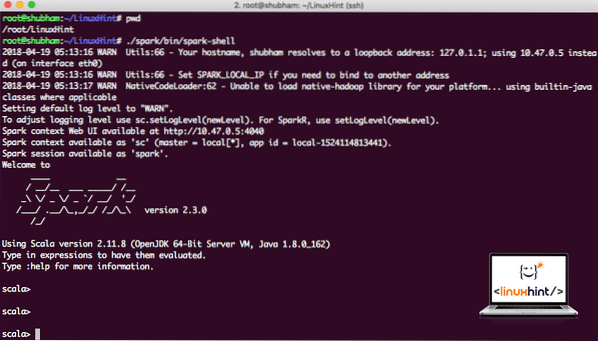
Spark Shell starten
Wir können in der Konsole sehen, dass Spark auch eine Webkonsole auf Port 404 geöffnet hat. Besuchen wir es:
Apache Spark-Webkonsole
Obwohl wir auf der Konsole selbst arbeiten werden, ist die Webumgebung ein wichtiger Ort, an dem Sie sich bei der Ausführung schwerer Spark-Jobs ansehen sollten, damit Sie wissen, was in jedem ausgeführten Spark-Job passiert.
Überprüfen Sie die Spark-Shell-Version mit einem einfachen Befehl:
sc.AusführungWir werden etwas zurückbekommen wie:
res0: Zeichenfolge = 2.3.0Erstellen einer Spark-Beispielanwendung mit Scala
Jetzt erstellen wir eine Beispielanwendung für den Wortzähler mit Apache Spark. Laden Sie dazu zunächst eine Textdatei in Spark Context auf der Spark-Shell:
scala> var Daten = sc.textFile("/root/LinuxHint/spark/README.md")Daten: org.Apache.Funke.rdd.RDD[String] = /root/LinuxHint/spark/README.md MapPartitionsRDD[1] at textFile at:24
Skala>
Nun muss der in der Datei vorhandene Text in Token aufgeteilt werden, die Spark verwalten kann:
scala> var-Token = Daten.flatMap(s => s.Teilt(" "))Token: org.Apache.Funke.rdd.RDD[String] = MapPartitionsRDD[2] bei flatMap bei :25
Skala>
Initialisieren Sie nun die Zählung für jedes Wort auf 1:
scala> var Token_1 = Token =.Karte(s => (s,1))tokens_1: org.Apache.Funke.rdd.RDD[(String, Int)] = MapPartitionsRDD[3] at map at :25
Skala>
Berechnen Sie schließlich die Häufigkeit jedes Wortes der Datei:
var sum_each = Token_1.ReduceByKey((a, b) => a + b)Zeit, sich die Ausgabe für das Programm anzusehen. Sammle die Token und ihre jeweilige Anzahl:
scala> sum_each.sammeln()res1: Array[(String, Int)] = Array((Paket,1), (For,3), (Programme,1), (Verarbeitung.,1), (Weil,1), (Der,1), (Seite](http://spark.Apache.Organisation/Dokumentation.html).,1), (Cluster).,1), (its,1), ([run,1), (als,1), (APIs,1), (have,1), (Try,1), (computation,1), (through,1 ), (mehrere,1), (This,2), (graph,1), (Hive,2), (Speicher,1), (["Specifying,1), (To,2), ("Garn" ,1), (Einmal,1), (["Nützlich,1), (bevorzugt,1), (SparkPi,2), (Engine,1), (Version,1), (Datei,1), (Dokumentation ,,1), (Verarbeitung,,1), (die,24), (sind,1), (Systeme.,1), (params,1), (not,1), (anders,1), (refer,2), (Interactive,2), (R,,1), (gegeben.,1), (if,4), (build,4), (when,1), (be,2), (Tests,1), (Apache,1), (Thread,1), (Programme,,1 ), (einschließlich,4), (./bin/run-example,2), (Spark.,1 Paket.,1), (1000).count(),1), (Versionen,1), (HDFS,1), (D…
Skala>
Ausgezeichnet! Wir konnten ein einfaches Word Counter-Beispiel mit der Programmiersprache Scala mit einer bereits im System vorhandenen Textdatei ausführen.
Fazit
In dieser Lektion haben wir uns angesehen, wie wir Apache Spark unter Ubuntu 17 installieren und verwenden können.10-Maschine und führen Sie auch eine Beispielanwendung darauf aus.
Lesen Sie hier mehr Ubuntu-basierte Beiträge.


