Dies ist ein Folgeartikel zum vorherigen. Wir werden behandeln, wie Sie die Abfrage verfeinern, komplexere Suchkriterien mit verschiedenen Parametern formulieren und die verschiedenen Webformulare der Apache Solr-Abfrageseite verstehen understand. Außerdem werden wir besprechen, wie das Suchergebnis mit verschiedenen Ausgabeformaten wie XML, CSV und JSON nachbearbeitet wird.
Abfragen von Apache Solr
Apache Solr ist als Webanwendung und -dienst konzipiert, die im Hintergrund ausgeführt werden. Das Ergebnis ist, dass jede Client-Anwendung mit Solr kommunizieren kann, indem sie Abfragen an sie sendet (im Mittelpunkt dieses Artikels), den Dokumentkern durch Hinzufügen, Aktualisieren und Löschen indizierter Daten manipulieren und Kerndaten optimieren. Es gibt zwei Möglichkeiten - über das Dashboard/Webinterface oder über eine API durch Senden einer entsprechenden Anfrage.
Es ist üblich, die erste Wahl zu Testzwecken und nicht für den regulären Zugriff. Die folgende Abbildung zeigt das Dashboard der Apache Solr Administration User Interface mit den verschiedenen Abfrageformularen im Webbrowser Firefox.
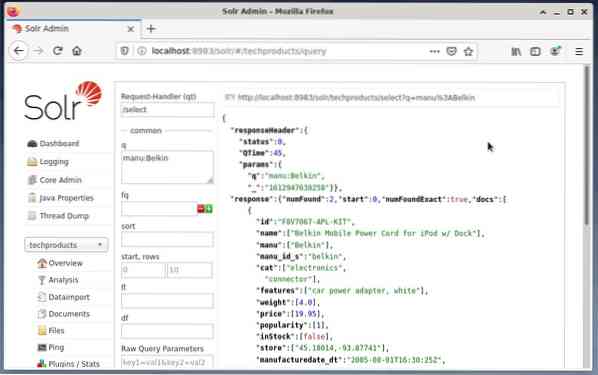
Wählen Sie zunächst aus dem Menü unter dem Kernauswahlfeld den Menüeintrag „Abfrage“. Als nächstes zeigt das Dashboard mehrere Eingabefelder wie folgt an:
- Request-Handler (qt):
Definieren Sie, welche Art von Anfrage Sie an Solr senden möchten. Sie können zwischen den Standard-Request-Handlern „/select“ (indizierte Daten abfragen), „/update“ (indizierte Daten aktualisieren) und „/delete“ (die angegebenen indizierten Daten entfernen) oder einem selbstdefinierten wählen. - Abfrageereignis (q):
Definieren Sie, welche Feldnamen und Werte ausgewählt werden sollen. - Abfragen filtern (fq):
Beschränken Sie die Obermenge der Dokumente, die zurückgegeben werden können, ohne die Dokumentenbewertung zu beeinflussen. - Sortierreihenfolge (sortieren):
Definieren Sie die Sortierreihenfolge der Abfrageergebnisse entweder auf aufsteigend oder absteigend - Ausgabefenster (Start und Zeilen):
Beschränken Sie die Ausgabe auf die angegebenen Elemente - Feldliste (fl):
Beschränkt die in einer Abfrageantwort enthaltenen Informationen auf eine angegebene Liste von Feldern. - Ausgabeformat (wt):
Definieren Sie das gewünschte Ausgabeformat. Der Standardwert ist JSON.
Durch Klicken auf die Schaltfläche Execute Query wird die gewünschte Anfrage ausgeführt. Praktische Beispiele finden Sie unten.
Als die zweite Option, Sie können eine Anfrage über eine API senden. Dies ist eine HTTP-Anfrage, die von jeder Anwendung an Apache Solr gesendet werden kann. Solr verarbeitet die Anfrage und gibt eine Antwort zurück. Ein Sonderfall davon ist die Verbindung zu Apache Solr über die Java-API. Dies wurde in ein separates Projekt namens SolrJ [7] ausgelagert - eine Java-API, die keine HTTP-Verbindung erfordert.
Abfragesyntax
Die Abfragesyntax ist am besten in [3] und [5] beschrieben. Die verschiedenen Parameternamen korrespondieren direkt mit den Namen der Eingabefelder in den oben erklärten Formularen. In der folgenden Tabelle sind sie sowie praktische Beispiele aufgeführt.
Abfrageparameter-Index
| Parameter | Beschreibung | Beispiel |
|---|---|---|
| q | Der wichtigste Abfrageparameter von Apache Solr - die Feldnamen und -werte. Ihre Ähnlichkeitsbewertungen dokumentieren die Begriffe in diesem Parameter. | ID: 5 Autos:*adilla* *:X5 |
| fq | Beschränken Sie die Ergebnismenge auf die übergeordneten Dokumente, die dem Filter entsprechen, z. B. definiert über Function Range Query Parser | Modell- ID, Modell |
| Start | Offsets für Seitenergebnisse (Anfang). Der Standardwert dieses Parameters ist 0. | 5 |
| Reihen | Offsets für Seitenergebnisse (Ende). Der Wert dieses Parameters ist standardmäßig 10 | fünfzehn |
| Sortieren | Sie gibt die durch Kommas getrennte Liste der Felder an, nach denen die Abfrageergebnisse sortiert werden sollen | Modell asc |
| fl | Es gibt die Liste der Felder an, die für alle Dokumente in der Ergebnismenge zurückgegeben werden sollen | Modell- ID, Modell |
| wt | Dieser Parameter stellt den Typ des Antwortschreibers dar, den wir als Ergebnis anzeigen wollten. Der Wert hierfür ist standardmäßig JSON. | json xml |
Die Suche erfolgt über eine HTTP-GET-Anfrage mit dem Abfragestring im Parameter qq. Die folgenden Beispiele verdeutlichen, wie das funktioniert. In Verwendung ist curl, um die Abfrage an Solr zu senden, das lokal installiert ist.
- Rufen Sie alle Datensätze aus den Kernfahrzeugen curl http://localhost:8983/solr/cars/query . ab?q=*:*
- Rufen Sie alle Datensätze von den Kernfahrzeugen ab, die eine ID von 5 haben curl http://localhost:8983/solr/cars/query?q=id:5
- Rufen Sie das Feldmodell aus allen Datensätzen der Kernfahrzeuge ab
Option 1 (mit Escapezeichen &): curl http://localhost:8983/solr/cars/query?q=id:*\&fl=ModellOption 2 (Abfrage in einzelnen Ticks):
curl 'http://localhost:8983/solr/cars/query?q=id:*&fl=Modell' - Rufen Sie alle Datensätze der Kernfahrzeuge absteigend sortiert nach Preis ab und geben Sie nur die Felder Marke, Modell und Preis aus (Version in einzelnen Ticks): curl http://localhost:8983/solr/cars/query -d '
q=*:*&
sort=Preis desc&
fl=Marke,Modell,Preis ' - Rufen Sie die ersten fünf Datensätze der Kernfahrzeuge absteigend nach Preis sortiert ab und geben Sie nur die Felder Marke, Modell und Preis aus (Version in einzelnen Ticks): curl http://localhost:8983/solr/cars/query - d'
q=*:*&
Zeilen=5&
sort=Preis desc&
fl=Marke,Modell,Preis ' - Rufen Sie die ersten fünf Datensätze der Kernfahrzeuge absteigend nach Preis sortiert ab und geben Sie nur die Felder Marke, Modell und Preis sowie deren Relevanzbewertung aus (Version in einzelnen Ticks): curl http://localhost:8983/solr/ Autos/Abfrage -d '
q=*:*&
Zeilen=5&
sort=Preis desc&
fl=machen,Modell,Preis,Punktzahl ' - Geben Sie alle gespeicherten Felder sowie die Relevanzbewertung zurück: curl http://localhost:8983/solr/cars/query -d '
q=*:*&
fl=*,Score '
Darüber hinaus können Sie Ihren eigenen Request-Handler definieren, um die optionalen Request-Parameter an den Query-Parser zu senden, um zu kontrollieren, welche Informationen zurückgegeben werden.
Abfrage-Parser
Apache Solr verwendet einen sogenannten Abfrageparser – eine Komponente, die Ihren Suchstring in spezifische Anweisungen für die Suchmaschine übersetzt translate. Zwischen Ihnen und dem gesuchten Dokument steht ein Abfrageparser.
Solr wird mit einer Vielzahl von Parser-Typen geliefert, die sich in der Art und Weise unterscheiden, wie eine gesendete Abfrage verarbeitet wird. Der Standard Query Parser funktioniert gut für strukturierte Abfragen, ist aber weniger tolerant gegenüber Syntaxfehlern. Gleichzeitig sind sowohl der DisMax als auch der Extended DisMax Query Parser für natürlichsprachliche Abfragen optimiert. Sie sind darauf ausgelegt, von Benutzern eingegebene einfache Phrasen zu verarbeiten und über mehrere Felder hinweg nach einzelnen Begriffen mit unterschiedlicher Gewichtung zu suchen.
Darüber hinaus bietet Solr auch sogenannte Function Queries an, die es ermöglichen, eine Funktion mit einer Anfrage zu kombinieren, um einen bestimmten Relevanz-Score zu generieren. Diese Parser heißen Function Query Parser und Function Range Query Parser. Das folgende Beispiel zeigt das letztere, um alle Datensätze für „bmw“ (gespeichert im Datenfeld Marke) mit den Modellen von 318 bis 323 auszuwählen:
curl http://localhost:8983/solr/cars/query -d 'q=machen: bmw&
fq=Modell:[318 TO 323] '
Nachbearbeitung der Ergebnisse
Das Senden von Abfragen an Apache Solr ist der eine Teil, die Nachbearbeitung des Suchergebnisses der andere other. Zunächst können Sie zwischen verschiedenen Antwortformaten wählen – von JSON über XML, CSV und einem vereinfachten Ruby-Format. Geben Sie einfach den entsprechenden wt-Parameter in einer Abfrage an. Das folgende Codebeispiel zeigt dies zum Abrufen des Datasets im CSV-Format für alle Elemente, die curl mit Escapezeichen & verwenden:
curl http://localhost:8983/solr/cars/query?q=id:5\&wt=csvDie Ausgabe ist eine durch Kommas getrennte Liste wie folgt:

Um das Ergebnis als XML-Daten zu erhalten, aber nur die beiden Ausgabefelder make und model, führen Sie die folgende Abfrage aus:
curl http://localhost:8983/solr/cars/query?q=*:*\&fl=make,model\&wt=xmlDie Ausgabe ist unterschiedlich und enthält sowohl den Antwortheader als auch die eigentliche Antwort:
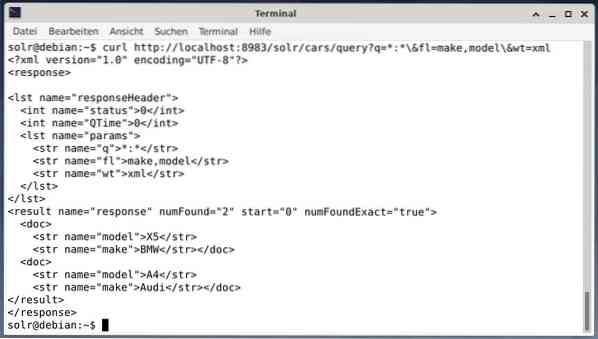
Wget druckt die empfangenen Daten einfach auf stdout. Auf diese Weise können Sie die Antwort mit Standardbefehlszeilentools nachbearbeiten. Um nur einige aufzulisten, enthält dies jq [9] für JSON, xsltproc, xidel, xmlstarlet [10] für XML sowie csvkit [11] für das CSV-Format.
Fazit
Dieser Artikel zeigt verschiedene Möglichkeiten zum Senden von Abfragen an Apache Solr und erklärt, wie das Suchergebnis verarbeitet wird. Im nächsten Teil erfahren Sie, wie Sie mit Apache Solr in PostgreSQL suchen, einem relationalen Datenbankverwaltungssystem search.
Über die Autoren
Jacqui Kabeta ist Umweltschützerin, begeisterte Forscherin, Trainerin und Mentorin. In mehreren afrikanischen Ländern hat sie in der IT-Branche und im NGO-Umfeld gearbeitet.
Frank Hofmann ist IT-Entwickler, Trainer und Autor und arbeitet am liebsten von Berlin, Genf und Kapstadt aus. Co-Autor des Debian Package Management Book, erhältlich bei dpmbd.org
Links und Referenzen
- [1] Apache Solr, https://lucene.Apache.org/solr/
- [2] Frank Hofmann und Jacqui Kabeta: Einführung in Apache Solr. Teil 1, http://linuxhint.com
- [3] Yonik Seelay: Solr-Abfragesyntax, http://yonik.com/solr/query-syntax/
- [4] Yonik Seelay: Solr-Tutorial, http://yonik.com/solr-Tutorial/
- [5] Apache Solr: Daten abfragen, Tutorialspoint, https://www.Tutorialspunkt.com/apache_solr/apache_solr_querying_data.htm
- [6] Lucene, https://lucene.Apache.Organisation/
- [7] SolrJ, https://lucene.Apache.org/solr/guide/8_8/using-solrj.html
- [8] curl, https://curl.se/
- [9] jq, https://github.com/stedolan/jq
- [10] xmlstarlet, http://xmlstar.Quellenschmiede.Netz/
- [11] csvkit, https://csvkit.readthedocs.io/de/neueste/


