Dies ist ein Folgeartikel zu den beiden vorherigen [2,3]. Bisher haben wir indizierte Daten in den Apache Solr-Speicher geladen und Daten dazu abgefragt. Jetzt erfahren Sie, wie Sie das relationale Datenbankmanagementsystem PostgreSQL [4] mit Apache Solr verbinden und mit den Fähigkeiten von Solr darin suchen. Dies macht es notwendig, mehrere Schritte durchzuführen, die unten detaillierter beschrieben werden - PostgreSQL einrichten, eine Datenstruktur in einer PostgreSQL-Datenbank vorbereiten und PostgreSQL mit Apache Solr verbinden und unsere Suche durchführen.
Schritt 1: PostgreSQL einrichten
Über PostgreSQL - eine kurze Info
PostgreSQL ist ein ausgeklügeltes objektrelationales Datenbankverwaltungssystem. Es ist einsatzbereit und wird seit über 30 Jahren aktiv weiterentwickelt. Es stammt von der University of California, wo es als Nachfolger von Ingres gilt [7].
Von Anfang an steht es unter Open Source (GPL) zur Verfügung, kann kostenlos verwendet, modifiziert und verteilt werden. Es ist weit verbreitet und in der Branche sehr beliebt. PostgreSQL wurde ursprünglich nur für die Ausführung auf UNIX/Linux-Systemen entwickelt und wurde später für die Ausführung auf anderen Systemen wie Microsoft Windows, Solaris und BSD entwickelt. Die aktuelle Entwicklung von PostgreSQL wird weltweit von zahlreichen Freiwilligen durchgeführt.
PostgreSQL-Setup
Falls noch nicht geschehen, installieren Sie PostgreSQL-Server und -Client lokal, zum Beispiel unter Debian GNU/Linux wie unten beschrieben mit apt. Zwei Artikel befassen sich mit PostgreSQL - Yunis Saids Artikel [5] befasst sich mit dem Setup auf Ubuntu. Trotzdem kratzt er nur an der Oberfläche, während mein vorheriger Artikel sich auf die Kombination von PostgreSQL mit der GIS-Erweiterung PostGIS konzentriert [6]. Die Beschreibung hier fasst alle Schritte zusammen, die wir für dieses spezielle Setup benötigen.
# apt install postgresql-13 postgresql-client-13Überprüfen Sie als Nächstes, ob PostgreSQL mit Hilfe des Befehls pg_isready ausgeführt wird. Dies ist ein Dienstprogramm, das Teil des PostgreSQL-Pakets ist.
# pg_isready/var/run/postgresql:5432 - Verbindungen werden akzeptiert
Die obige Ausgabe zeigt, dass PostgreSQL bereit ist und auf eingehende Verbindungen auf Port 5432 wartet. Sofern nicht anders eingestellt, ist dies die Standardkonfiguration. Der nächste Schritt ist das Festlegen des Passworts für den UNIX-Benutzer Postgres:
# passwd PostgresDenken Sie daran, dass PostgreSQL eine eigene Benutzerdatenbank hat, während der administrative PostgreSQL-Benutzer Postgres noch kein Passwort hat. Der vorherige Schritt muss auch für den PostgreSQL-Benutzer Postgres durchgeführt werden:
# su - Postgres$ psql -c "ALTER USER Postgres MIT PASSWORT 'password';"
Der Einfachheit halber ist das gewählte Passwort nur ein Passwort und sollte auf anderen Systemen als Testing durch eine sicherere Passwortphrase ersetzt werden. Der obige Befehl ändert die interne Benutzertabelle von PostgreSQL. Beachten Sie die unterschiedlichen Anführungszeichen - das Passwort in einfachen Anführungszeichen und die SQL-Abfrage in doppelten Anführungszeichen, um zu verhindern, dass der Shell-Interpreter den Befehl falsch auswertet. Fügen Sie außerdem ein Semikolon nach der SQL-Abfrage vor den doppelten Anführungszeichen am Ende des Befehls hinzu.
Als nächstes verbinden Sie sich aus administrativen Gründen als Benutzer Postgres mit dem zuvor erstellten Passwort. Der Befehl heißt psql:
$ psqlDie Verbindung von Apache Solr zur PostgreSQL-Datenbank erfolgt als Benutzer solr. Fügen wir also den PostgreSQL-Benutzer solr hinzu und setzen wir auf einmal ein entsprechendes Passwort solr für ihn:
$ BENUTZER SOLR MIT PASSWD 'solr' ERSTELLEN;Der Einfachheit halber lautet das gewählte Passwort nur solr und sollte auf Systemen, die in Produktion sind, durch eine sicherere Passwortphrase ersetzt werden.
Schritt 2: Vorbereiten einer Datenstruktur
Zum Speichern und Abrufen von Daten wird eine entsprechende Datenbank benötigt. Der folgende Befehl erstellt eine Datenbank mit Autos, die dem Benutzer solr gehört und später verwendet wird.
$ DATENBANK ERSTELLEN Autos MIT EIGENTÜMER = solr;Verbinden Sie sich dann mit der neu erstellten Datenbank cars als Benutzer solr cars. Die Option -d (kurze Option für -dbname) definiert den Datenbanknamen und -U (kurze Option für -username) den Namen des PostgreSQL-Benutzers.
$ psql -d cars -U solrEine leere Datenbank ist nicht sinnvoll, aber strukturierte Tabellen mit Inhalten schon. Erstellen Sie die Struktur der Tischwagen wie folgt:
$ TABELLE ERSTELLEN Autos (id int,
machen varchar(100),
Modell varchar(100),
Beschreibung varchar(100),
Farbe varchar(50),
Preis int
);
Die Tabelle cars enthält sechs Datenfelder - id (integer), make (ein String der Länge 100), model (ein String der Länge 100), description (ein String der Länge 100), color (ein String der Länge 50) und Preis (Ganzzahl). Um einige Beispieldaten zu erhalten, fügen Sie der Tabelle Autos die folgenden Werte als SQL-Anweisungen hinzu:
$ INSERT INTO Autos (ID, Marke, Modell, Beschreibung, Farbe, Preis)WERTE (1, 'BMW', 'X5', 'Cool Car', 'Grau', 45000);
$ INSERT INTO Autos (ID, Marke, Modell, Beschreibung, Farbe, Preis)
WERTE (2, „Audi“, „Quattro“, „Rennwagen“, „weiß“, 30000);
Das Ergebnis sind zwei Einträge, die einen grauen BMW X5 darstellen, der 45000 USD kostet und als cooles Auto bezeichnet wird, und einen weißen Rennwagen Audi Quattro, der 30000 USD kostet.
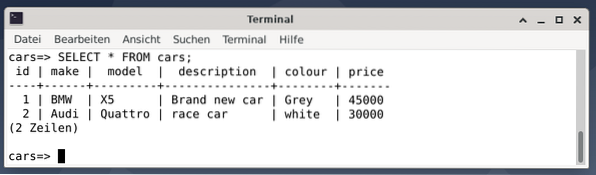
Beenden Sie als Nächstes die PostgreSQL-Konsole mit \q oder beenden Sie.
$ \qSchritt 3: PostgreSQL mit Apache Solr verbinden
Die Verbindung von PostgreSQL und Apache Solr basiert auf zwei Softwarekomponenten – einem Java-Treiber für PostgreSQL namens Java Database Connectivity (JDBC)-Treiber und einer Erweiterung der Solr-Serverkonfiguration. Der JDBC-Treiber fügt PostgreSQL eine Java-Schnittstelle hinzu, und der zusätzliche Eintrag in der Solr-Konfiguration teilt Solr mit, wie eine Verbindung zu PostgreSQL mithilfe des JDBC-Treibers hergestellt wird.
Das Hinzufügen des JDBC-Treibers erfolgt als Benutzer root wie folgt und installiert den JDBC-Treiber aus dem Debian-Paket-Repository:
# apt-get install libpostgresql-jdbc-javaAuf Apache Solr-Seite muss auch ein entsprechender Knoten vorhanden sein. Falls noch nicht geschehen, erstellen Sie als UNIX-Benutzer solr die Node Cars wie folgt:
$ bin/solr create -c AutosAls nächstes erweitern Sie die Solr-Konfiguration für den neu erstellten Knoten created. Fügen Sie die folgenden Zeilen zur Datei /var/solr/data/cars/conf/solrconfig . hinzu.xml:
db-data-config.xmlErstellen Sie außerdem eine Datei /var/solr/data/cars/conf/data-config.xml und speichern Sie den folgenden Inhalt darin:
Die Zeilen oben entsprechen den vorherigen Einstellungen und definieren den JDBC-Treiber, geben den Port 5432 für die Verbindung zum PostgreSQL-DBMS als Benutzer solr mit dem entsprechenden Passwort an und stellen die SQL-Abfrage so ein, dass sie von PostgreSQL ausgeführt werden soll. Der Einfachheit halber handelt es sich um eine SELECT-Anweisung, die den gesamten Inhalt der Tabelle erfasst.
Starten Sie als Nächstes den Solr-Server neu, um Ihre Änderungen zu aktivieren. Führen Sie als Benutzer root den folgenden Befehl aus:
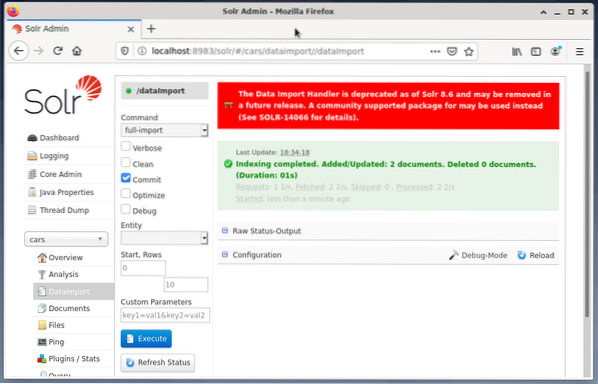
# systemctl restart solrDer letzte Schritt ist der Import der Daten, beispielsweise über das Solr-Webinterface. Die Knotenauswahlbox wählt die Knotenautos aus, dann aus dem Knotenmenü unter dem Eintrag Datenimport gefolgt von der Auswahl des vollständigen Imports aus dem Befehlsmenü rechts daneben. Drücken Sie abschließend die Schaltfläche Ausführen. Die folgende Abbildung zeigt, dass Solr die Daten erfolgreich indiziert hat.
Schritt 4: Abfragen von Daten aus dem DBMS
Der vorherige Artikel [3] befasst sich ausführlich mit der Abfrage von Daten, dem Abrufen des Ergebnisses und der Auswahl des gewünschten Ausgabeformats - CSV, XML oder JSON. Das Abfragen der Daten erfolgt ähnlich wie Sie es zuvor gelernt haben, und für den Benutzer ist kein Unterschied sichtbar. Solr erledigt die gesamte Arbeit hinter den Kulissen und kommuniziert mit dem PostgreSQL-DBMS, das wie im ausgewählten Solr-Kern oder -Cluster definiert verbunden ist.
Die Verwendung von Solr ändert sich nicht und Abfragen können über die Solr-Administrationsoberfläche oder mit curl oder wget auf der Befehlszeile gesendet werden. Sie senden eine Get-Anfrage mit einer bestimmten URL an den Solr-Server (Abfrage, Aktualisierung oder Löschung). Solr verarbeitet die Anfrage unter Verwendung des DBMS als Speichereinheit und gibt das Ergebnis der Anfrage zurück. Verarbeiten Sie als Nächstes die Antwort lokal nach.
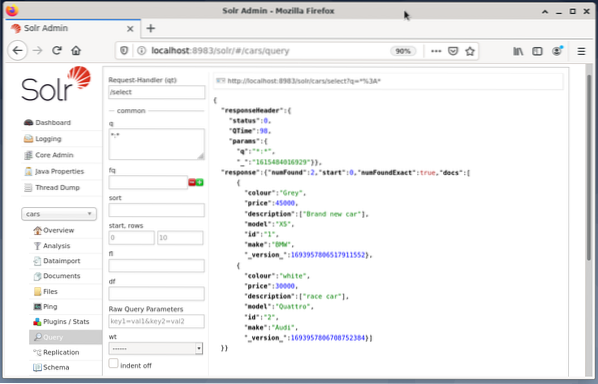
Das folgende Beispiel zeigt die Ausgabe der Abfrage „/select“?q=*. *” im JSON-Format in der Solr-Admin-Oberfläche. Die Daten werden aus der Datenbank Autos abgerufen, die wir zuvor erstellt haben.
Fazit
Dieser Artikel zeigt, wie Sie eine PostgreSQL-Datenbank von Apache Solr abfragen und erklärt das entsprechende Setup. Im nächsten Teil dieser Serie erfahren Sie, wie Sie mehrere Solr-Knoten zu einem Solr-Cluster zusammenfassen.
Über die Autoren
Jacqui Kabeta ist Umweltschützerin, begeisterte Forscherin, Trainerin und Mentorin. In mehreren afrikanischen Ländern hat sie in der IT-Branche und im NGO-Umfeld gearbeitet.
Frank Hofmann ist IT-Entwickler, Trainer und Autor und arbeitet am liebsten von Berlin, Genf und Kapstadt aus. Co-Autor des Debian Package Management Book, erhältlich bei dpmbd.org
Links und Referenzen
- [1] Apache Solr, https://lucene.Apache.org/solr/
- [2] Frank Hofmann und Jacqui Kabeta: Einführung in Apache Solr. Teil 1, https://linuxhint.com/apache-solr-setup-a-node/
- [3] Frank Hofmann und Jacqui Kabeta: Einführung in Apache Solr. Daten abfragen. Teil 2, http://linuxhint.com
- [4] PostgreSQL, https://www.postgresql.Organisation/
- [5] Younis Said: So installieren und konfigurieren Sie die PostgreSQL-Datenbank unter Ubuntu 20.04, https://linuxhint.com/install_postgresql_-ubuntu/
- [6] Frank Hofmann: Einrichten von PostgreSQL mit PostGIS auf Debian GNU/Linux 10, https://linuxhint.com/setup_postgis_debian_postgres/
- [7] Ingres, Wikipedia, https://en.Wikipedia.org/wiki/Ingres_(Datenbank)


