Web-Scraping-Tutorials wurden in der Vergangenheit behandelt, daher behandelt dieses Tutorial nur den Aspekt des Zugriffs auf Websites durch Einloggen mit Code, anstatt dies manuell über den Browser zu tun.
Um dieses Tutorial zu verstehen und Skripte für die Anmeldung bei Websites schreiben zu können, benötigen Sie einige HTML-Kenntnisse. Vielleicht nicht genug, um großartige Websites zu erstellen, aber genug, um die Struktur einer einfachen Webseite zu verstehen.
Installation
Dies würde mit den Python-Bibliotheken Requests und BeautifulSoup erfolgen. Abgesehen von diesen Python-Bibliotheken benötigen Sie einen guten Browser wie Google Chrome oder Mozilla Firefox, da sie für die erste Analyse vor dem Schreiben von Code wichtig wären.
Die Bibliotheken Requests und BeautifulSoup können mit dem Befehl pip vom Terminal aus installiert werden, wie unten gezeigt:
Pip-Installationsanfragenpip installieren BeautifulSoup4
Um den Erfolg der Installation zu bestätigen, aktivieren Sie die interaktive Shell von Python, die durch Eingabe von Python ins Terminal.
Importieren Sie dann beide Bibliotheken:
Importanfragenaus bs4 importieren BeautifulSoup
Der Import ist erfolgreich, wenn keine Fehler vorliegen.
Der Prozess
Die Anmeldung bei einer Website mit Skripten erfordert HTML-Kenntnisse und eine Vorstellung davon, wie das Web funktioniert. Schauen wir uns kurz an, wie das Web funktioniert.
Websites bestehen aus zwei Hauptteilen, der clientseitigen und der serverseitigen. Die Client-Seite ist der Teil einer Website, mit dem der Benutzer interagiert, während die Server-Seite der Teil der Website ist, in dem Geschäftslogik und andere Serveroperationen wie der Zugriff auf die Datenbank ausgeführt werden.
Wenn Sie versuchen, eine Website über ihren Link zu öffnen, stellen Sie eine Anfrage an den Server, um die HTML-Dateien und andere statische Dateien wie CSS und JavaScript abzurufen. Diese Anfrage wird als GET-Anfrage bezeichnet. Wenn Sie jedoch ein Formular ausfüllen, eine Mediendatei oder ein Dokument hochladen, einen Beitrag erstellen und beispielsweise auf eine Schaltfläche zum Senden klicken, senden Sie Informationen an die Serverseite. Diese Anfrage wird als POST-Anfrage bezeichnet.
Beim Schreiben unseres Drehbuchs wäre es wichtig, diese beiden Konzepte zu verstehen.
Überprüfung der Website
Um die Konzepte dieses Artikels zu üben, würden wir die Quotes To Scrape-Website verwenden.
Für die Anmeldung bei Websites sind Informationen wie Benutzername und Passwort erforderlich.
Da diese Website jedoch nur als Proof of Concept verwendet wird, ist alles möglich. Daher würden wir verwenden Administrator als Benutzername und 12345 als Passwort.
Zunächst ist es wichtig, sich die Seitenquelle anzusehen, da dies einen Überblick über die Struktur der Webseite geben würde. Dies können Sie tun, indem Sie mit der rechten Maustaste auf die Webseite klicken und auf „Seitenquelle anzeigen“ klicken. Als nächstes inspizieren Sie das Login-Formular. Sie tun dies, indem Sie mit der rechten Maustaste auf eines der Login-Felder klicken und auf klicken Element prüfen. Bei der Überprüfung des Elements sollten Sie Folgendes sehen: Eingang Tags und dann ein Elternteil bilden markiere irgendwo darüber. Dies zeigt, dass Logins im Grunde Formulare sind, die POSTauf die Serverseite der Website übertragen.
Beachten Sie nun die Name Attribut der Eingabe-Tags für die Felder für Benutzername und Passwort, werden sie beim Schreiben des Codes benötigt. Für diese Website ist die Name Attribut für den Benutzernamen und das Passwort sind Nutzername und Passwort beziehungsweise.
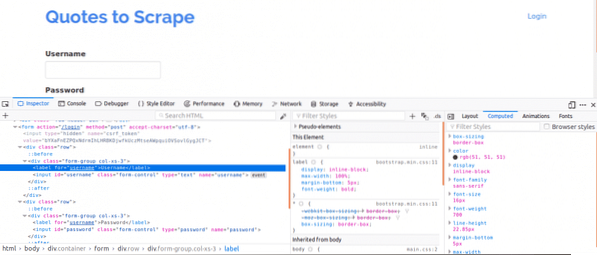
Als nächstes müssen wir wissen, ob es andere Parameter gibt, die für die Anmeldung wichtig wären. Lass uns das schnell erklären. Um die Sicherheit von Websites zu erhöhen, werden in der Regel Token generiert, um Cross Site Forgery-Angriffe zu verhindern.
Wenn diese Token der POST-Anfrage nicht hinzugefügt werden, schlägt die Anmeldung daher fehl. Woher wissen wir also von solchen Parametern??
Wir müssten die Registerkarte "Netzwerk" verwenden. Um diese Registerkarte in Google Chrome oder Mozilla Firefox zu erhalten, öffnen Sie die Entwicklertools und klicken Sie auf die Registerkarte Netzwerk.
Sobald Sie sich im Netzwerk-Tab befinden, versuchen Sie, die aktuelle Seite zu aktualisieren, und Sie werden feststellen, dass Anfragen eingehen coming. Sie sollten darauf achten, dass POST-Anfragen gesendet werden, wenn wir versuchen, uns anzumelden.
Folgendes würden wir als Nächstes tun, während die Registerkarte „Netzwerk“ geöffnet ist. Geben Sie die Anmeldedaten ein und versuchen Sie, sich anzumelden. Die erste Anfrage, die Sie sehen würden, sollte die POST-Anfrage sein be.
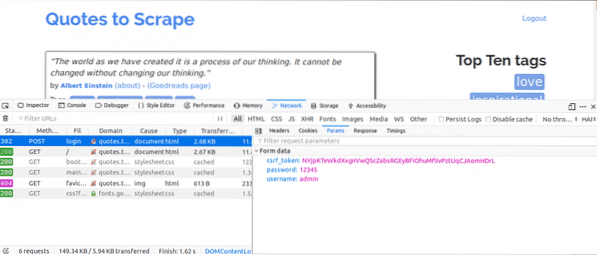
Klicken Sie auf die POST-Anfrage und sehen Sie sich die Formularparameter an. Sie würden feststellen, dass die Website ein csrf_token Parameter mit Wert. Dieser Wert ist ein dynamischer Wert, daher müssten wir solche Werte mit dem erfassen ERHALTEN fordern Sie zuerst an, bevor Sie die POST Anfrage.
Bei anderen Websites, an denen Sie arbeiten würden, sehen Sie das möglicherweise nicht csrf_token aber es kann andere Token geben, die dynamisch generiert werden. Im Laufe der Zeit werden Sie die Parameter besser kennen, die bei einem Login-Versuch wirklich wichtig sind.
Der Code
Zunächst müssen wir Requests und BeautifulSoup verwenden, um Zugriff auf den Seiteninhalt der Anmeldeseite zu erhalten.
aus Anfragen importieren Sessionvon bs4 importieren BeautifulSoup als bs
mit Session() als s:
Seite = s.get("http://zitate.kratzen.com/login")
drucken (site.Inhalt)
Dies würde den Inhalt der Login-Seite ausdrucken, bevor wir uns einloggen und wenn Sie nach dem Stichwort „Login“ suchen. Das Schlüsselwort würde im Seiteninhalt gefunden und zeigt, dass wir uns noch anmelden müssen.
Als nächstes würden wir nach dem suchen csrf_token Schlüsselwort, das als einer der Parameter gefunden wurde, wenn Sie zuvor die Registerkarte Netzwerk verwendet haben. Wenn das Keyword eine Übereinstimmung mit einem . anzeigt Eingang Tag, dann kann der Wert jedes Mal extrahiert werden, wenn Sie das Skript mit BeautifulSoup ausführen.
aus Anfragen importieren Sessionvon bs4 importieren BeautifulSoup als bs
mit Session() als s:
Seite = s.get("http://zitate.kratzen.com/login")
bs_content = bs(site.Inhalt, "html.Parser")
Token = bs_content.find("input", "name":"csrf_token")["value"]
login_data = "username":"admin","password":"12345", "csrf_token":token
so.post("http://zitate.kratzen.com/login",login_data)
home_page = s.get("http://zitate.kratzen.com")
drucken(home_page.Inhalt)
Dies würde den Inhalt der Seite drucken, nachdem Sie sich angemeldet haben und nach dem Schlüsselwort „Logout“ suchen. Das Schlüsselwort wäre im Seiteninhalt zu finden und zeigt an, dass wir uns erfolgreich einloggen konnten.
Schauen wir uns jede Codezeile an.
aus Anfragen importieren Sessionvon bs4 importieren BeautifulSoup als bs
Die obigen Codezeilen werden verwendet, um das Session-Objekt aus der Request-Bibliothek und das BeautifulSoup-Objekt aus der bs4-Bibliothek unter Verwendung eines Alias von . zu importieren bs.
mit Session() als s:Die Anfragesitzung wird verwendet, wenn Sie beabsichtigen, den Kontext einer Anfrage beizubehalten, damit die Cookies und alle Informationen dieser Anfragesitzung gespeichert werden können.
bs_content = bs(site.Inhalt, "html.Parser")Token = bs_content.find("input", "name":"csrf_token")["value"]
Dieser Code hier verwendet die BeautifulSoup-Bibliothek, damit die csrf_token kann von der Webseite extrahiert und dann der Token-Variablen zugewiesen werden. Erfahren Sie mehr über das Extrahieren von Daten aus Knoten mit BeautifulSoup.
login_data = "username":"admin","password":"12345", "csrf_token":tokenso.post("http://zitate.kratzen.com/login", login_data)
Der Code hier erstellt ein Wörterbuch der Parameter, die für die Anmeldung verwendet werden sollen. Die Schlüssel der Wörterbücher sind die Name Attribute der Input-Tags und der Werte sind die Wert Attribute der Input-Tags.
Das Post -Methode wird verwendet, um eine Postanfrage mit den Parametern zu senden und uns einzuloggen.
home_page = s.get("http://zitate.kratzen.com")drucken(home_page.Inhalt)
Nach einer Anmeldung extrahieren diese obigen Codezeilen einfach die Informationen von der Seite, um zu zeigen, dass die Anmeldung erfolgreich war.
Fazit
Der Prozess der Anmeldung bei Websites mit Python ist recht einfach, aber die Einrichtung von Websites ist nicht gleich, daher erweisen sich einige Websites als schwieriger einzuloggen als andere. Es gibt noch mehr, was Sie tun können, um Ihre Login-Herausforderungen zu meistern.
Das Wichtigste bei all dem ist die Kenntnis von HTML, Requests, BeautifulSoup und die Fähigkeit, die Informationen aus der Registerkarte Netzwerk der Entwicklertools Ihres Webbrowsers zu verstehen.


