In dieser Lektion wollen wir das tun. Wir werden herausfinden, wie Werte verschiedener HTML-Tags extrahiert werden können und auch die Standardfunktionalität dieses Moduls überschreiben, um eine eigene Logik hinzuzufügen. Wir werden dies mit der HTMLParser Klasse in Python in html.Parser Modul. Sehen wir uns den Code in Aktion an.
Betrachten der HTMLParser-Klasse
Um HTML-Text in Python zu parsen, können wir verwenden HTMLParser Klasse in html.Parser Modul. Schauen wir uns die Klassendefinition für die an HTMLParser Klasse:
Klasse html.Parser.HTMLParser(*, convert_charrefs=True)Das convert_charrefs Wenn es auf True gesetzt ist, werden alle Zeichenreferenzen in ihre Unicode-Äquivalente konvertiert. Nur der Skript/Stil Elemente werden nicht konvertiert. Jetzt werden wir versuchen, auch jede Funktion für diese Klasse zu verstehen, um besser zu verstehen, was jede Funktion tut.
- handle_startendtag Dies ist die erste Funktion, die ausgelöst wird, wenn ein HTML-String an die Klasseninstanz übergeben wird. Sobald der Text hier ankommt, wird die Kontrolle an andere Funktionen in der Klasse übergeben, die sich auf andere Tags im String einschränkt. Dies ist auch in der Definition dieser Funktion klar: def handle_startendtag(self, tag, attrs):
selbst.handle_starttag(tag, attrs)
selbst.handle_endtag(tag) - handle_starttag: Diese Methode verwaltet das Start-Tag für die empfangenen Daten. Seine Definition ist wie unten gezeigt: def handle_starttag(self, tag, attrs):
bestehen - handle_endtag: Diese Methode verwaltet das End-Tag für die empfangenen Daten: def handle_endtag(self, tag):
bestehen - handle_charref: Diese Methode verwaltet die Zeichenreferenzen in den empfangenen Daten. Seine Definition ist wie unten gezeigt: def handle_charref(self, name):
bestehen - handle_entityref: Diese Funktion verarbeitet die Entity-Referenzen im an sie übergebenen HTML: def handle_entityref(self, name):
bestehen - handle_data:Dies ist die Funktion, bei der echte Arbeit geleistet wird, um Werte aus den HTML-Tags zu extrahieren und die Daten zu jedem Tag übergeben. Seine Definition ist wie unten gezeigt: def handle_data(self, data):
bestehen - handle_comment: Mit dieser Funktion können wir auch Kommentare an eine HTML-Quelle anhängen: def handle_comment(self, data):
bestehen - handle_pi: Da HTML auch Verarbeitungsanweisungen haben kann, ist dies die Funktion, in der diese ausgeführt werden. Ihre Definition ist wie folgt: def handle_pi(self, data):
bestehen - handle_decl: Diese Methode behandelt die Deklarationen im HTML, ihre Definition ist wie folgt: def handle_decl(self, decl):
bestehen
Unterklassen der HTMLParser-Klasse
In diesem Abschnitt werden wir die HTMLParser-Klasse unterklassen und einen Blick auf einige der Funktionen werfen, die aufgerufen werden, wenn HTML-Daten an die Klasseninstanz übergeben werden. Lassen Sie uns ein einfaches Skript schreiben, das all dies tut:
von html.Parser-Import HTMLParserKlasse LinuxHTMLParser(HTMLParser):
def handle_starttag(self, tag, attrs):
print("Start-Tag gefunden:", Tag)
def handle_endtag(self, tag):
print("End-Tag gefunden:", Tag)
def handle_data(self, data):
print("Daten gefunden:", Daten)
Parser = LinuxHTMLParser()
Parser.Futter("
'
Python-HTML-Parsing-Modul
')
Folgendes erhalten wir mit diesem Befehl zurück:
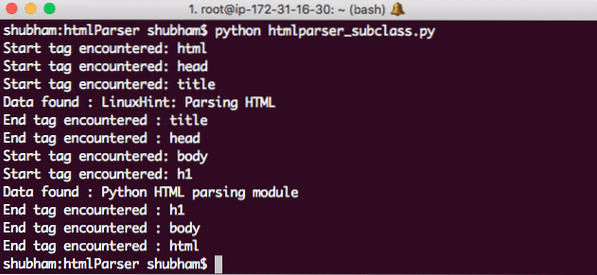
Python HTMLParser-Unterklasse
HTMLParser-Funktionen
In diesem Abschnitt werden wir mit verschiedenen Funktionen der HTMLParser-Klasse arbeiten und uns die jeweilige Funktionalität ansehen:
von html.Parser-Import HTMLParservon html.Entitäten importieren name2codepoint
Klasse LinuxHint_Parse(HTMLParser):
def handle_starttag(self, tag, attrs):
print("Start-Tag:", Tag)
für attr in attrs:
print(" attr:", attr)
def handle_endtag(self, tag):
print("End-Tag:", Tag)
def handle_data(self, data):
print("Daten:", Daten)
def handle_comment(self, data):
print("Kommentar:", Daten)
def handle_entityref(self, name):
c = chr(name2codepoint[name])
print("Benannte Ent:", c)
def handle_charref(self, name):
wenn name.beginntmit('x'):
c = chr(int(name[1:], 16))
sonst:
c = chr(int(name))
print("Zahl :", c)
def handle_decl(self, data):
print("Decl:", Daten)
Parser = LinuxHint_Parse()
Lassen Sie uns mit verschiedenen Aufrufen dieser Instanz separate HTML-Daten zuführen und sehen, welche Ausgabe diese Aufrufe erzeugen. Wir beginnen mit einem einfachen DOCTYP Zeichenfolge:
Parser.Futter(''"http://www.w3.org/TR/html4/strict.dtd">')Das bekommen wir mit diesem Anruf zurück:
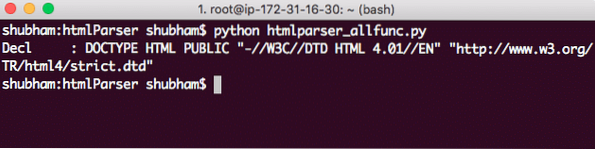
DOCTYPE-String
Lassen Sie uns nun ein Image-Tag ausprobieren und sehen, welche Daten es extrahiert:
Parser.Futter(' ')
') Mit diesem Anruf bekommen wir folgendes zurück:

HTMLParser-Image-Tag
Als Nächstes versuchen wir, wie sich das script-Tag mit Python-Funktionen verhält:
Parser.Futter('')Parser.Futter('')
Parser.feed('#python color: green')
Mit diesem Anruf bekommen wir folgendes zurück:

Skript-Tag im htmlparser
Schließlich übergeben wir auch Kommentare an den HTMLParser-Abschnitt:
Parser.Futter('''')
Mit diesem Anruf bekommen wir folgendes zurück:

Kommentare analysieren
Fazit
In dieser Lektion haben wir uns angeschaut, wie wir HTML mit der Python-eigenen HTMLParser-Klasse ohne eine andere Bibliothek analysieren können. Wir können den Code leicht ändern, um die Quelle der HTML-Daten in einen HTTP-Client zu ändern.
Lesen Sie hier mehr Python-basierte Beiträge.


