Einführung
Ein Baum in Software ist wie ein biologischer Baum, jedoch mit folgenden Unterschieden:
- Es ist verkehrt herum gezeichnet.
- Es hat nur eine Wurzel und keinen Stamm.
- Die Zweige gehen aus der Wurzel hervor.
- Ein Punkt, an dem ein Zweig von einem anderen Zweig oder der Wurzel abgeht, wird als Knoten bezeichnet.
- Jeder Knoten hat einen Wert.
Die Zweige des Softwarebaums werden durch gerade Linien dargestellt. Ein gutes Beispiel für einen Softwarebaum, den Sie möglicherweise verwendet haben, ist der Verzeichnisbaum der Festplatte Ihres Computers.
Es gibt verschiedene Baumarten. Es gibt den allgemeinen Baum, von dem andere Bäume abgeleitet sind. Andere Bäume werden abgeleitet, indem Beschränkungen in den allgemeinen Baum eingeführt werden. Sie möchten beispielsweise einen Baum, bei dem nicht mehr als zwei Zweige von einem Knoten ausgehen; ein solcher Baum würde als Binärbaum bezeichnet. Dieser Artikel beschreibt den allgemeinen Baum und den Zugriff auf alle seine Knoten.
Der Hyperlink zum Herunterladen des Codes befindet sich am Ende dieses Artikels.
Um die Codebeispiele in diesem Artikel zu verstehen, benötigen Sie Grundkenntnisse in JavaScript (ECMAScript). Wenn Sie dieses Wissen nicht haben, können Sie es unter http://www.breites Netzwerk.com/ChrysanthusForcha-1/ECMAScript-2015-Kurs.htm
Das allgemeine Baumdiagramm
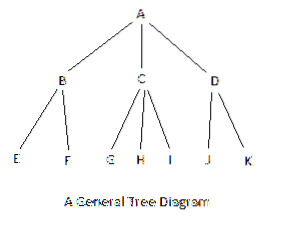
'A' ist der Wurzelknoten; es ist der Knoten der ersten Ebene. B, C, D stehen in der zweiten Zeile; das sind Knoten der zweiten Ebene. E, F, G, H, I, J, K befinden sich auf der dritten Zeile und sind Knoten der dritten Ebene. Eine vierte Zeile hätte Knoten der vierten Ebene erzeugt, und so weiter.
Baumeigenschaften
- Alle Zweige für alle Knotenebenen haben eine Quelle, die der Wurzelknoten ist.
- Ein Baum hat N - 1 Zweige, wobei N die Gesamtzahl der Knoten ist. Das obige Diagramm für den allgemeinen Baum hat 11 Knoten und 10 Zweige.
- Anders als beim Menschen, wo jedes Kind zwei Elternteile hat, hat beim Softwarebaum jedes Kind nur ein Elternteil. Der Wurzelknoten ist der größte Vorfahren-Elternteil. Ein Elternteil kann mehr als ein Kind haben. Jeder Knoten außer dem Wurzelknoten ist ein Kind.
Baumwortschatz
- Wurzelknoten: Dies ist der höchste Knoten im Baum, und er hat kein übergeordnetes Element. Jeder andere Knoten hat ein Elternteil.
- Blattknoten: Ein Blattknoten ist ein Knoten ohne Kind. Sie befinden sich normalerweise am unteren Ende des Baumes und manchmal an der linken und/oder rechten Seite des Baumes.
- Schlüssel: Das ist der Wert eines Baumes. Es kann eine Zahl sein; es kann eine Zeichenfolge sein; es kann sogar ein Operator wie + oder - oder x . sein.
- Ebenen: Der Wurzelknoten befindet sich auf der ersten Ebene. Seine Kinder sind auf der zweiten Ebene; Die Kinder der Knoten der zweiten Ebene befinden sich auf der dritten Ebene und so weiter.
- Elternknoten: Jeder Knoten, mit Ausnahme des Wurzelknotens, hat einen Elternknoten, der durch eine Verzweigung mit ihm verbunden ist. Jeder Knoten, mit Ausnahme des Wurzelknotens, ist ein untergeordneter Knoten.
- Geschwisterknoten: Geschwisterknoten sind Knoten, die den gleichen Elternknoten haben.
- Pfad: Die Zweige (gerade Linien), die einen Knoten durch andere Knoten mit einem anderen verbinden, bilden einen Pfad. Die Zweige können Pfeile sein oder nicht not.
- Vorfahrenknoten: Alle höheren Knoten, die mit einem Kind verbunden sind, einschließlich des Eltern- und des Wurzelknotens, sind Vorfahrenknoten.
- Nachkommender Knoten: Alle unteren Knoten, die mit einem Knoten verbunden sind, bis hin zu verbundenen Blättern, sind Nachkommenknoten. Der betreffende Knoten gehört nicht zu den Nachkommenknoten. Der fragliche Knoten muss nicht der Wurzelknoten sein.
- Unterbaum: Ein Knoten plus alle seine Nachkommen bis hin zu den zugehörigen Blättern bilden einen Teilbaum. Der Startknoten ist enthalten und muss nicht die Wurzel sein; sonst wäre es der ganze Baum.
- Grad: Die Anzahl der Kinder, die ein Knoten hat, wird als Grad des Knotens bezeichnet.
Durchqueren aller Knoten eines Baums
Auf alle Knoten eines Baums kann zugegriffen werden, um jeden Wert des Knotens zu lesen oder zu ändern. Dies geschieht jedoch nicht willkürlich. Es gibt drei Möglichkeiten, dies zu tun, die alle die Depth-First-Traversal wie folgt beinhalten:
1) In der Reihenfolge: Einfach ausgedrückt wird in diesem Schema zuerst der linke Teilbaum durchlaufen; dann wird auf den Wurzelknoten zugegriffen; dann wird der rechte Teilbaum durchlaufen. Dieses Schema wird als links->wurzel->rechts symbolisiert. Abb. 1 wird hier zur leichteren Bezugnahme erneut angezeigt:
Angenommen, es gibt zwei Geschwister pro Knoten; dann links->root->rechts bedeutet, dass Sie zuerst auf den untersten und den ganz linken Knoten zugreifen, dann auf den Elternknoten des Knotens und dann auf den rechten Geschwisterknoten. Wenn es mehr als zwei Geschwister gibt, nimm den ersten als den linken und den Rest der rechten Knoten als den rechten. Für den obigen allgemeinen Baum wird auf den unteren linken Teilbaum zugegriffen, [EBF]. Dies ist ein Unterbaum. Der Elternteil dieses Teilbaums ist A; also wird als nächstes auf A zugegriffen, um [EBF]A . zu haben. Als nächstes wird auf den Teilbaum [GCHI] zugegriffen, um einen größeren Teilbaum zu haben, [[EBF]A[GCHI]]. Sie können das linke->root->rechte Profil sehen, das sich selbst darstellt. Dieser große linke Teilbaum hat den Teilbaum [JDK] zu seiner Rechten, um die Durchquerung abzuschließen, um [[EBF]A[GCHI]] [JDK] zu erhalten.
2) Vorbestellung: Einfach ausgedrückt, in diesem Schema wird zuerst auf den Wurzelknoten zugegriffen, dann wird der linke Teilbaum als nächstes durchlaufen und dann wird der rechte Teilbaum durchlaufen. Dieses Schema wird als root->links->rechts symbolisiert. Abb. 1 wird hier zur leichteren Bezugnahme erneut angezeigt.
Angenommen, es gibt zwei Geschwister pro Knoten; dann root->left->right bedeutet, dass Sie zuerst auf die Wurzel zugreifen, dann auf das linke unmittelbare Kind und dann auf das rechte unmittelbare Kind. Wenn es mehr als zwei Geschwister gibt, nimm den ersten als den linken und den Rest der rechten Knoten als den rechten. Das am weitesten links stehende Kind des linken Kindes ist das nächste, auf das zugegriffen wird. Für den obigen allgemeinen Baum ist der Wurzelteilbaum [ABCD]. Links von diesem Teilbaum befindet sich der Teilbaum [EF] mit der Zugriffsfolge [ABCD][EF]. Rechts von diesem größeren Unterbaum haben Sie zwei Unterbäume, [GHI] und [JK], die die vollständige Sequenz ergeben, [ABCD][EF][GHI][JK]. Sie können das Root->Links->Rechtsprofil sehen, das sich selbst darstellt.
3) Nachbestellung: Einfach ausgedrückt, in diesem Schema wird zuerst der linke Teilbaum durchlaufen, dann wird der rechte Teilbaum durchlaufen und dann wird auf die Wurzel zugegriffen. Dieses Schema wird als links->rechts->root> symbolisiert. Abb. 1 wird hier zur leichteren Bezugnahme erneut angezeigt.
Für diesen Baum sind die Unterbäume [EFB], [GHIC], [JKD] und [A], die die Sequenz bilden, [EFB], [GHIC], [JKD][A]. Sie können das Links->Rechts->Root-Profil sehen, das sich selbst darstellt.
Den Baum erstellen
Der obige Baum wird mit ECMAScript erstellt, das wie die neueste Version von JavaScript ist. Jeder Knoten ist ein Array. Das erste Element jedes Knotenarrays ist das Elternelement des Knotens, ein weiteres Array. Die restlichen Elemente des Knotens sind die Kinder des Knotens, beginnend mit dem ganz linken Kind. Es gibt eine ECMAScript-Zuordnung, die jedes Array mit seinem entsprechenden String (Buchstaben) in Beziehung setzt. Das erste Codesegment ist: