Beginnen wir mit einer naiven Definition von „Staatenlosigkeit“ und schreiten wir dann langsam zu einer strengeren und realitätsnahen Sichtweise fort.
Eine zustandslose Anwendung ist eine Anwendung, die auf keinen persistenten Speicher angewiesen ist. Das einzige, wofür Ihr Cluster verantwortlich ist, ist der Code und andere statische Inhalte, die darauf gehostet werden. Das war's, keine wechselnden Datenbanken, keine Schreibvorgänge und keine übrig gebliebenen Dateien, wenn der Pod gelöscht wird.
Eine zustandsbehaftete Anwendung hingegen hat mehrere andere Parameter, die sie im Cluster betreuen soll. Es gibt dynamische Datenbanken, die, auch wenn die App offline ist oder gelöscht wird, auf der Festplatte verbleiben. Auf einem verteilten System wie Kubernetes wirft dies mehrere Probleme auf. Wir werden sie uns im Detail ansehen, aber lassen Sie uns zunächst einige Missverständnisse klären.
Zustandslose Dienste sind nicht wirklich "zustandslos"
Was bedeutet es, wenn wir den Zustand eines Systems sagen?? Betrachten wir das folgende einfache Beispiel einer automatischen Tür.
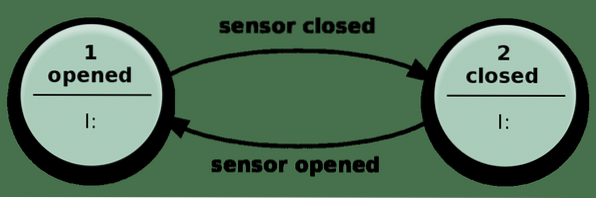
Die Tür öffnet sich, wenn der Sensor erkennt, dass sich jemand nähert, und schließt sich, wenn der Sensor keine relevanten Eingaben erhält.
In der Praxis ähnelt Ihre zustandslose App diesem Mechanismus oben. Es kann viel mehr Zustände als nur geschlossen oder geöffnet haben und viele verschiedene Arten von Eingaben machen es komplexer, aber im Wesentlichen gleich.
Es kann komplizierte Probleme lösen, indem es nur eine Eingabe empfängt und Aktionen ausführt, die sowohl von der Eingabe als auch vom "Zustand" abhängen, in dem sie sich befindet. Die Anzahl der möglichen Zustände ist vordefiniert.
Staatenlosigkeit ist also eine Fehlbezeichnung.
Zustandslose Anwendungen können in der Praxis auch ein wenig schummeln, indem sie beispielsweise Details zu den Client-Sitzungen auf dem Client selbst speichern (HTTP-Cookies sind ein gutes Beispiel) und trotzdem eine schöne Zustandslosigkeit aufweisen, die sie auf dem Cluster fehlerfrei laufen lässt.
Zum Beispiel können die Sitzungsdetails eines Kunden, z. B. welche Produkte im Warenkorb gespeichert und nicht ausgecheckt wurden, alle auf dem Kunden gespeichert werden und beim nächsten Beginn einer Sitzung werden diese relevanten Details ebenfalls gespeichert.
In einem Kubernetes-Cluster ist einer zustandslosen Anwendung kein persistenter Speicher oder Volume zugeordnet. Aus operativer Sicht sind das großartige Neuigkeiten. Verschiedene Pods im gesamten Cluster können unabhängig voneinander arbeiten, wobei mehrere Anfragen gleichzeitig eingehen. Wenn etwas schief geht, können Sie die Anwendung einfach neu starten und sie kehrt mit geringer Ausfallzeit in den Ausgangszustand zurück.
Stateful Services und das CAP-Theorem
Die zustandsbehafteten Dienste hingegen müssen sich um viele, viele Randfälle und seltsame Probleme kümmern. Ein Pod wird von mindestens einem Volume begleitet, und wenn die Daten in diesem Volume beschädigt sind, bleibt dies auch dann bestehen, wenn der gesamte Cluster neu gestartet wird.
Wenn Sie beispielsweise eine Datenbank in einem Kubernetes-Cluster ausführen, müssen alle Pods ein lokales Volume zum Speichern der Datenbank haben. Alle Daten müssen perfekt synchronisiert sein.
Wenn also jemand einen Eintrag in der Datenbank ändert, und das wurde in Pod A durchgeführt, und eine Leseanforderung in Pod B eingeht, um diese geänderten Daten zu sehen, muss Pod B die neuesten Daten anzeigen oder Ihnen eine Fehlermeldung ausgeben. Dies wird als Konsistenz bezeichnet.
Konsistenz, im Kontext eines Kubernetes-Clusters bedeutet jeder Lesevorgang erhält den letzten Schreibvorgang oder eine Fehlermeldung.
Aber das schneidet gegen Verfügbarkeit, einer der wichtigsten Gründe für ein verteiltes System. Verfügbarkeit bedeutet, dass Ihre Anwendung rund um die Uhr möglichst perfekt und fehlerfrei funktioniert.
Man könnte argumentieren, dass Sie all dies vermeiden können, wenn Sie nur eine zentrale Datenbank haben, die für die Handhabung aller persistenten Speicheranforderungen verantwortlich ist. Jetzt haben wir wieder einen Single Point of Failure, ein weiteres Problem, das ein Kubernetes-Cluster überhaupt lösen soll.
Sie benötigen eine dezentrale Möglichkeit, persistente Daten in einem Cluster zu speichern. Im Allgemeinen als Netzwerkpartitionierung bezeichnet. Darüber hinaus muss Ihr Cluster in der Lage sein, den Ausfall von Knoten zu überstehen, auf denen die zustandsorientierte Anwendung ausgeführt wird. Dies ist bekannt als Teilungstoleranz.
Jeder zustandsbehaftete Dienst (oder jede Anwendung), der auf einem Kubernetes-Cluster ausgeführt wird, muss ein Gleichgewicht zwischen diesen drei Parametern aufweisen. In der Branche ist es als CAP-Theorem bekannt, bei dem die Kompromisse zwischen Konsistenz und Verfügbarkeit in Gegenwart von Netzwerkpartitionierung berücksichtigt werden.
Weitere Referenzen
Für weitere Einblicke in das CAP-Theorem können Sie sich diesen ausgezeichneten Vortrag von Bryan Cantrill ansehen, der sich viel genauer mit dem Betrieb verteilter Systeme in der Produktion befasst.


